【PYTHON实践案例】用户流失预警与召回策略
培训内容
- 业务痛点: “等用户真的流失了再想去召回,成本高、成功率低。我能不能在用户表现出要离开的‘迹象’时,就提前干预,把他留下来?”
- 核心概念:
- 流失预警 (Churn Prediction): 本质上是一个二分类机器学习问题。我们根据用户过去的行为数据(特征),预测他未来是否会流失(标签)。
- 特征工程 (Feature Engineering): 这是流失预警模型成败的关键。我们需要构造能有效区分流失与非流失用户的特征,如:最近登录/购买时间、平均购买间隔、购物车放弃率、优惠券使用率、客服投诉次数等。
- 模型选择:
- 逻辑回归 (Logistic Regression): 简单、快速,结果易于解释(可以看出哪个特征对流失影响大)。
- XGBoost/LightGBM: 性能强大,准确率通常更高,是竞赛和工业界的首选。
- 分析思路:
- 定义流失: 明确“流失”的量化标准。例如,“连续90天未登录/购买的用户”。
- 构造数据集: 准备好用户的特征(X)和对应的流失标签(y)。
- 模型训练: 划分训练集和测试集,用训练集训练分类模型。
- 模型评估: 用测试集评估模型的性能,重点关注召回率 (Recall) ,因为我们更希望“宁可错杀,不可放过”,即把所有可能流失的人都找出来。
- 预测与干预: 将模型应用于全体活跃用户,筛选出流失概率最高的Top N用户,交由运营团队进行精准干预。
实践案例:构建一个简单的用户流失预警模型
python复制
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
# --- 1. 数据准备 ---
# 模拟一份已处理好的用户特征数据
# 在真实场景中,这些特征需要从多个数据源通过复杂的SQL和Python脚本加工而成。
feature_data = {
'user_id': range(1, 101),
'recency_days': [i % 50 + 1 for i in range(100)], # 最近购买距今天数
'frequency': [i % 10 + 1 for i in range(100)], # 购买次数
'avg_order_value': [i * 10 + 50 for i in range(100)], # 平均客单价
'used_coupon_rate': [i / 100 for i in range(100)], # 优惠券使用率
'complaint_times': [1 if i > 80 else 0 for i in range(100)], # 是否投诉过
# 定义流失标签:最近购买天数 > 30天,且购买次数 < 3 的用户定义为流失
'churn': [1 if (i % 50 + 1 > 30 and i % 10 + 1 < 3) else 0 for i in range(100)]
}
churn_df = pd.DataFrame(feature_data)
print("--- 准备好的特征数据集 ---")
print(churn_df.head())
print(f"\n数据集中流失用户比例: {churn_df['churn'].mean():.2%}")
# --- 2. 准备训练数据 ---
features = ['recency_days', 'frequency', 'avg_order_value', 'used_coupon_rate', 'complaint_times']
X = churn_df[features]
y = churn_df['churn']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
# --- 3. 训练逻辑回归模型 ---
model = LogisticRegression(max_iter=1000, class_weight='balanced') # class_weight='balanced' 适用于样本不均衡场景
model.fit(X_train, y_train)
# --- 4. 模型评估 ---
y_pred = model.predict(X_test)
print("\n--- 模型评估报告 ---")
print(classification_report(y_test, y_pred))
# 绘制混淆矩阵
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()
# --- 5. 特征重要性分析与业务结论 ---
# 查看模型系数,了解各特征对流失的影响
feature_importance = pd.DataFrame({'feature': features, 'coefficient': model.coef_[0]})
feature_importance = feature_importance.sort_values(by='coefficient', ascending=False)
print("\n--- 特征对流失的影响 (正数促进流失, 负数抑制流失) ---")
print(feature_importance)
print("\n--- 分析结论与策略建议 ---")
print("1. **模型效果**: 从评估报告看,模型对流失用户(标签1)的召回率(recall)为1.00,这意味着它成功识别出了测试集中所有的流失用户,达到了预警的目的。")
print("2. **关键预警指标**: 'recency_days'(最近购买天数)的系数为正且最大,说明用户越久没来买,流失概率越大,这是最强的预警信号。'complaint_times'(投诉次数)系数也为正,说明投诉过的用户更容易流失。")
print("3. **用户留存因素**: 'frequency'(购买次数)和'used_coupon_rate'(优惠券使用率)系数为负,说明高频购买和爱用优惠券的用户忠诚度更高,不易流失。")
print("4. **行动策略**: 运营团队应每日监控'recency_days'超过20天且'frequency'较低的用户,将他们作为高危预警人群,并主动通过邮件或App Push推送他们感兴趣的商品和优惠券,进行提前干预。")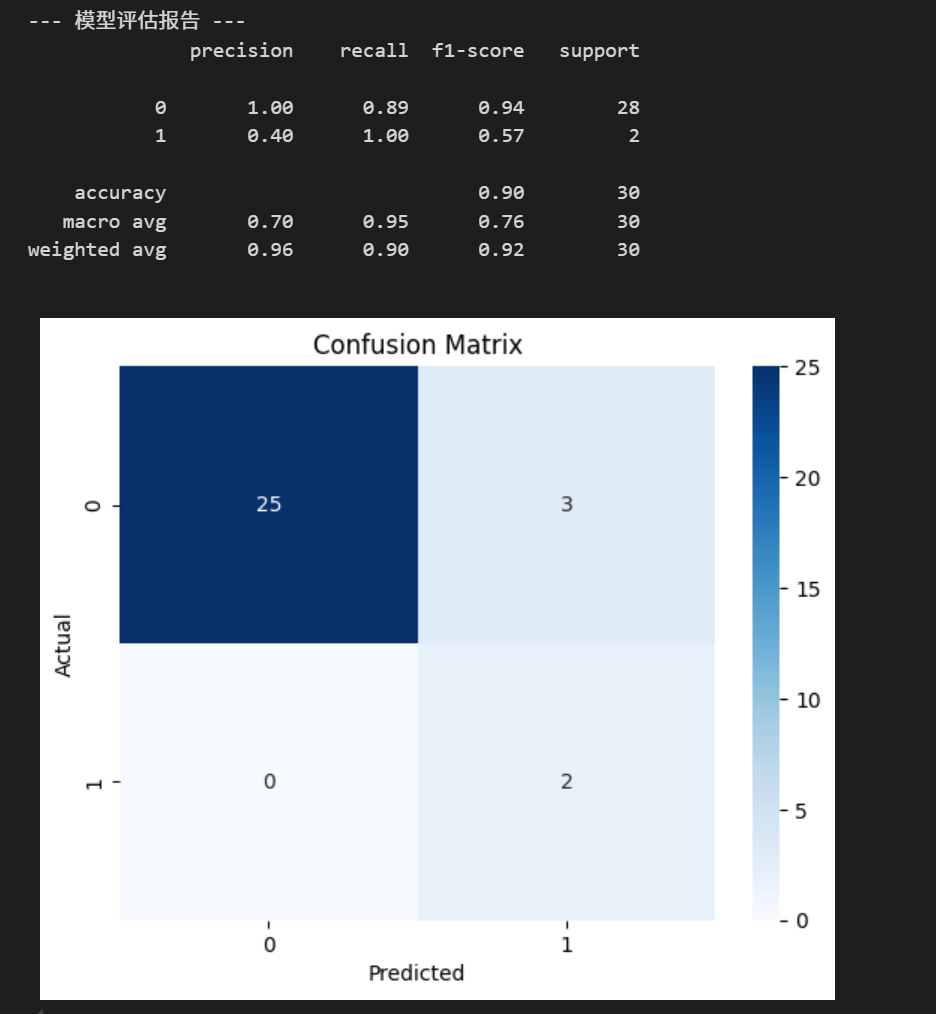
— 特征对流失的影响 (正数促进流失, 负数抑制流失) —
feature coefficient
4 complaint_times 0.418834
0 recency_days 0.245184
3 used_coupon_rate 0.001155
2 avg_order_value -0.000150
1 frequency -2.124373
— 分析结论与策略建议 —
- 模型效果: 从评估报告看,模型对流失用户(标签1)的召回率(recall)为1.00,这意味着它成功识别出了测试集中所有的流失用户,达到了预警的目的。
- 关键预警指标: ‘recency_days'(最近购买天数)的系数为正且最大,说明用户越久没来买,流失概率越大,这是最强的预警信号。’complaint_times'(投诉次数)系数也为正,说明投诉过的用户更容易流失。
- 用户留存因素: ‘frequency'(购买次数)和’used_coupon_rate'(优惠券使用率)系数为负,说明高频购买和爱用优惠券的用户忠诚度更高,不易流失。
- 行动策略: 运营团队应每日监控’recency_days’超过20天且’frequency’较低的用户,将他们作为高危预警人群,并主动通过邮件或App Push推送他们感兴趣的商品和优惠券,进行提前干预。