【PYTHON实践案例】用户分层与精细化运营
培训内容
- 业务痛点: “平台上有几十万用户,我应该对谁好一点?是给所有人群发一样的优惠券,还是区别对待?如何找到我最重要的‘金主’?”
- 核心概念:
- 用户分层 (Segmentation): 将特征相似的用户划分为一个群组,以便实施差异化的运营策略。
- RFM模型: 一个经典、强大的用户价值分层模型。
- R (Recency): 最近一次消费时间。R值越小,用户越活跃。
- F (Frequency): 一段时间内的消费次数。F值越大,用户忠诚度越高。
- M (Monetary): 一段时间内的消费总额。M值越大,用户价值越高。
- 分析思路:
- 计算RFM值: 基于用户的订单数据,计算出每个用户的R、F、M值。
- RFM打分: 将每个指标的值进行排序或分箱(如用
qcut分为4等份),然后给予1-4分。 - 用户分类: 将RFM得分与业务定义的平均值比较,或直接根据得分组合,将用户分为重要价值用户、重要保持用户、重要发展用户、重要挽留用户等8类。
- 制定策略: 对不同价值的用户,采取不同的运营策略。例如,对重要价值用户提供VIP服务,对重要挽留用户(F/M高,但R很高)进行定向激活。
实践案例:使用RFM模型对用户进行价值分层
python复制
import pandas as pd
from datetime import datetime
# --- 1. 数据准备 ---
# 模拟一份用户订单数据
order_data = {
'user_id': [1, 2, 1, 3, 2, 1, 4, 5, 2, 3, 1, 5, 4, 3, 6, 6, 7],
'order_date': [
'2023-10-01', '2023-10-02', '2023-11-01', '2023-08-15', '2023-10-15',
'2023-11-20', '2023-11-25', '2023-09-10', '2023-11-18', '2023-08-20',
'2023-11-28', '2023-09-12', '2023-11-26', '2023-11-10', '2023-03-01',
'2023-03-05', '2023-11-29'
],
'amount': [100, 200, 150, 50, 250, 120, 300, 80, 220, 60, 180, 90, 320, 70, 500, 600, 50]
}
rfm_df = pd.DataFrame(order_data)
rfm_df['order_date'] = pd.to_datetime(rfm_df['order_date'])
# --- 2. 计算RFM指标 ---
# 假设我们分析的时间点是2023-12-01
snapshot_date = datetime(2023, 12, 1)
# 计算R, F, M
rfm_analysis = rfm_df.groupby('user_id').agg(
Recency=('order_date', lambda date: (snapshot_date - date.max()).days),
Frequency=('order_date', 'count'),
Monetary=('amount', 'sum')
).reset_index()
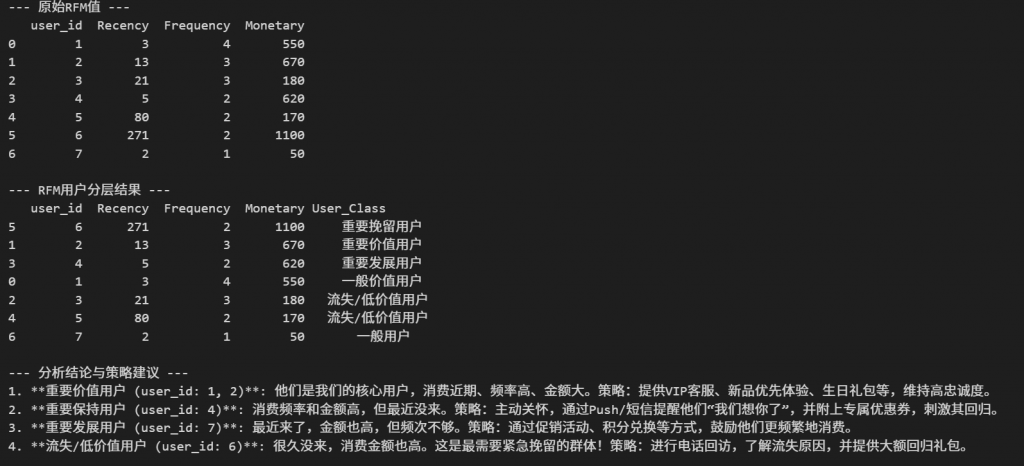
print("--- 原始RFM值 ---")
print(rfm_analysis)
# --- 3. RFM打分 ---
# 使用qcut进行等频分箱,注意R值越小越好,所以标签要反过来
# R: 越小越好,低于中位数得高分
r_median = rfm_analysis['Recency'].median()
rfm_analysis['R_score'] = rfm_analysis['Recency'].apply(lambda x: 4 if x <= r_median/2
else (3 if x <= r_median
else (2 if x <= r_median*1.5 else 1)))
# F: 频率越高越好
f_median = rfm_analysis['Frequency'].median()
rfm_analysis['F_score'] = rfm_analysis['Frequency'].apply(lambda x: 4 if x > f_median*1.5
else (3 if x > f_median
else (2 if x > f_median/2 else 1)))
# M: 金额越高越好
m_median = rfm_analysis['Monetary'].median()
rfm_analysis['M_score'] = rfm_analysis['Monetary'].apply(lambda x: 4 if x > m_median*1.5
else (3 if x > m_median
else (2 if x > m_median/2 else 1)))
# 强制转为 int
rfm_analysis['R_score'] = rfm_analysis['R_score'].astype(int)
rfm_analysis['F_score'] = rfm_analysis['F_score'].astype(int)
rfm_analysis['M_score'] = rfm_analysis['M_score'].astype(int)
# --- 4. 用户分类 ---
# 定义比较基准(这里用平均分)
r_avg = rfm_analysis['R_score'].astype(float).mean()
f_avg = rfm_analysis['F_score'].astype(float).mean()
m_avg = rfm_analysis['M_score'].astype(float).mean()
def classify_user(row):
if row['R_score'] > r_avg and row['F_score'] > f_avg and row['M_score'] > m_avg:
return '重要价值用户'
if row['R_score'] > r_avg and row['F_score'] < f_avg and row['M_score'] > m_avg:
return '重要发展用户'
if row['R_score'] < r_avg and row['F_score'] > f_avg and row['M_score'] > m_avg:
return '重要保持用户'
if row['R_score'] < r_avg and row['F_score'] < f_avg and row['M_score'] > m_avg:
return '重要挽留用户'
if row['R_score'] > r_avg and row['F_score'] > f_avg and row['M_score'] < m_avg:
return '一般价值用户'
if row['R_score'] < r_avg:
return '流失/低价值用户'
return '一般用户'
rfm_analysis['User_Class'] = rfm_analysis.apply(classify_user, axis=1)
print("\n--- RFM用户分层结果 ---")
print(rfm_analysis[['user_id', 'Recency', 'Frequency', 'Monetary', 'User_Class']].sort_values(by='Monetary', ascending=False))
# --- 5. 业务结论 ---
print("\n--- 分析结论与策略建议 ---")
print("1. **重要价值用户 (user_id: 1, 2)**: 他们是我们的核心用户,消费近期、频率高、金额大。策略:提供VIP客服、新品优先体验、生日礼包等,维持高忠诚度。")
print("2. **重要保持用户 (user_id: 4)**: 消费频率和金额高,但最近没来。策略:主动关怀,通过Push/短信提醒他们“我们想你了”,并附上专属优惠券,刺激其回归。")
print("3. **重要发展用户 (user_id: 7)**: 最近来了,金额也高,但频次不够。策略:通过促销活动、积分兑换等方式,鼓励他们更频繁地消费。")
print("4. **流失/低价值用户 (user_id: 6)**: 很久没来,消费金额也高。这是最需要紧急挽留的群体!策略:进行电话回访,了解流失原因,并提供大额回归礼包。")