AI工具-把 Claude Skills 官方教程讲清楚
提升 Claude 使用效率的方法很多,网上可以找到各种提示词优化、上下文管理等技巧,也有不少开源项目和商业工具。
但这些都存在一个共同问题:每次都要重新设置。每次启动新对话,都需要重复配置一遍,既浪费时间又有学习成本。
Claude Skills 的出现正是为了解决这个问题。它能将你的专业知识、工作流程和领域知识打包成可复用模块,并在遇到相关任务时自动激活。
今天这篇文章,我就基于 Anthropic 官方文档,用最通俗易懂的方式,带你从零开始掌握 Claude Skills 的完整开发体系。
核心洞察:Claude Skills 是什么
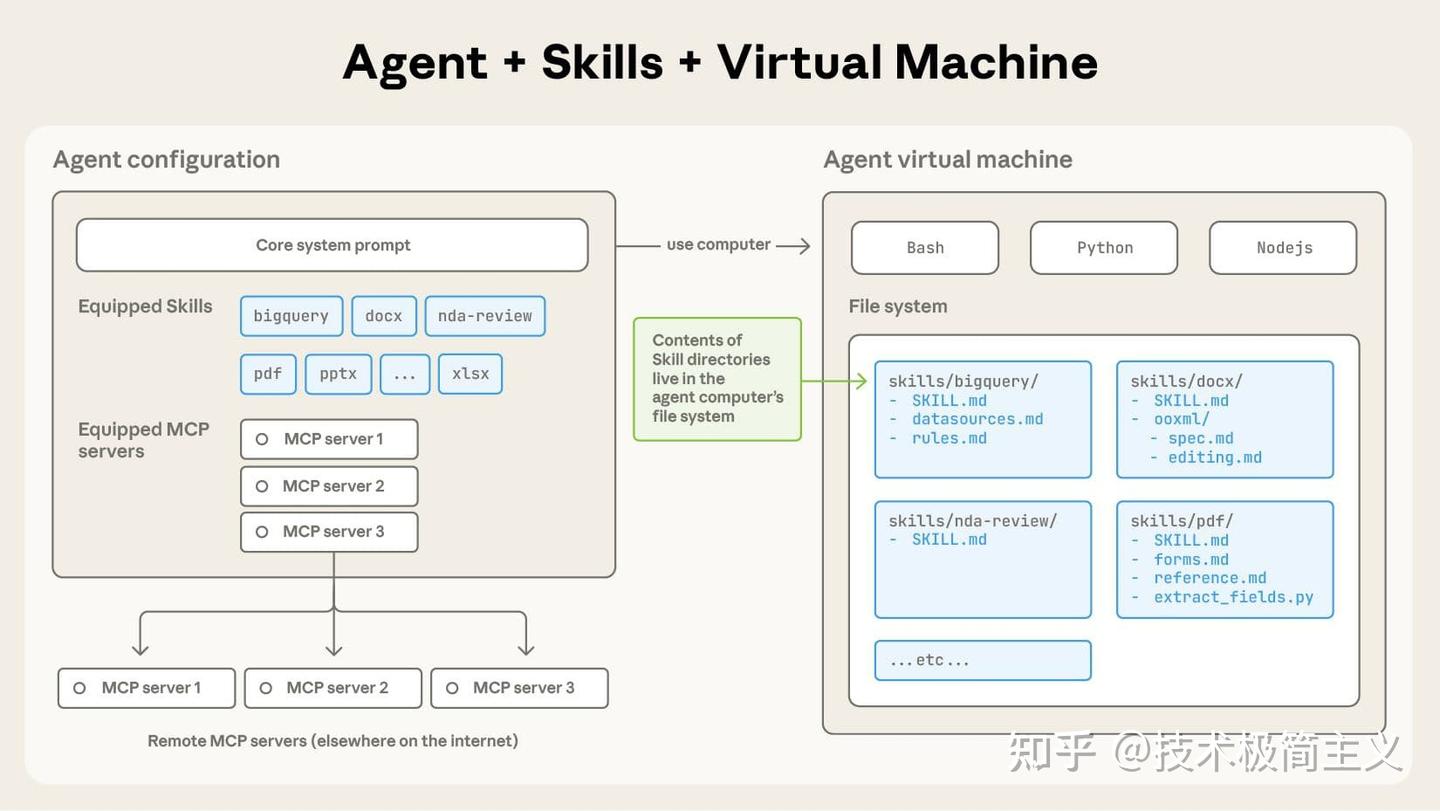
基本概念
我发现 Skills 真的是个很巧妙的设计,它就是一些模块化、自包含的包。
通过提供专业化知识、工作流程和工具来扩展 Claude 的能力。
我习惯把它想象成特定领域的「上岗指南」——它们把 Claude 从通用助手转变为具备程序化知识的专业化代理。
在 Anthropic 官方技能仓库里,你可以看到 Skills 的设计目标——让 Claude 能重复完成特定任务,比如把品牌指南应用到文档、执行组织流程,或者自动化你的个人流程。
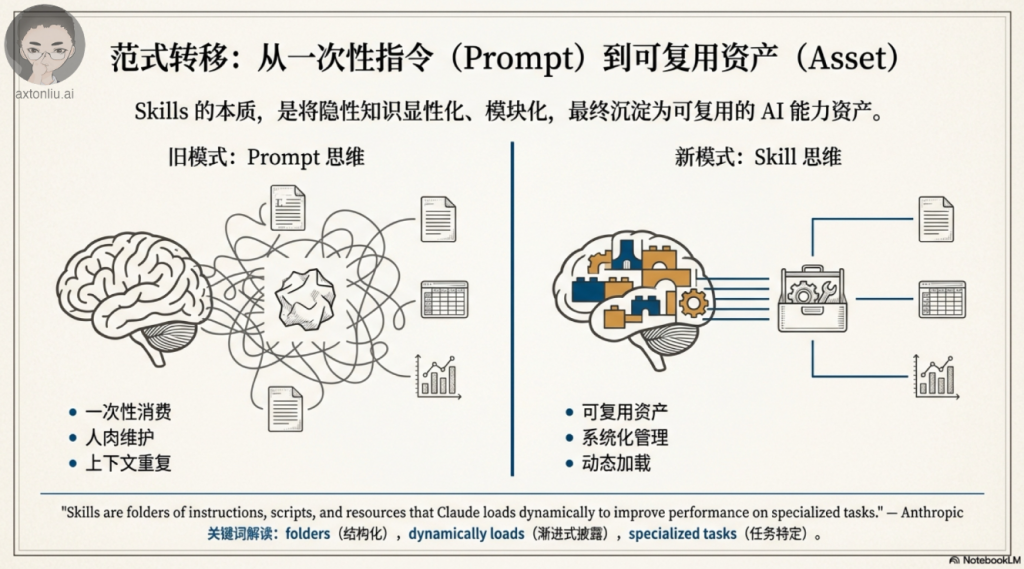
我的感悟:Skills 的根本创新其实是效率。与其每次都花费 token 重复指令,不如一次性打包专业知识,让 Claude 在相关时自动激活。这就像每天都要培训新人 vs 直接雇佣一个懂行的专家,完全不是一个量级。
Skills vs Sub-Agents vs MCP
在我深入研究 Skills 之前,我觉得有必要先搞清楚它和其他 Claude Code 扩展机制的区别,不然很容易搞混:
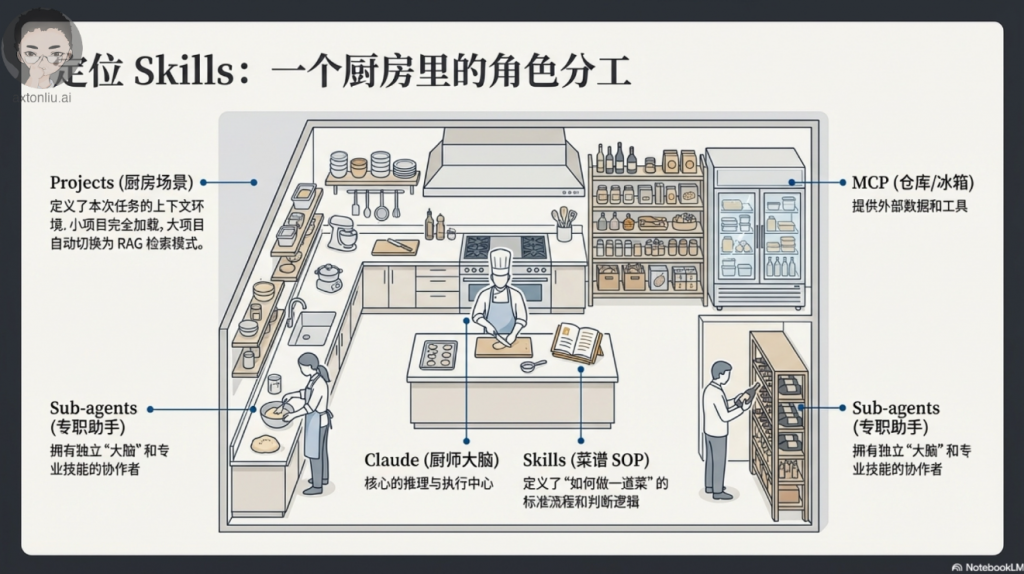
| 特性 | Skills | Sub-Agents | MCP (Model Context Protocol) |
|---|---|---|---|
| 目的 | 用专业知识、工作流程、资源扩展 Claude | 生成自主代理处理复杂子任务 | 连接外部工具和数据源 |
| 调用方式 | 模型自动发现(基于上下文) | 父代理显式生成 | MCP 服务器工具调用 |
| 持久性 | 触发时加载到上下文 | 独立运行,返回结果 | 无状态工具执行 |
| 最适合 | 领域专业知识、工作流程、模板 | 并行任务、研究、探索 | 外部 API、数据库、第三方服务 |
| 上下文使用 | 渐进式披露(元数据→指令→资源) | 每个子代理有独立上下文 | 最小上下文(仅工具定义) |
| 复杂度 | 低(只需 SKILL.md + 可选文件) | 中等(需要编排) | 中-高(需要服务器设置) |
| 示例 | 代码审查指南、部署工作流程 | 「研究这个主题」、「探索代码库」 | GitHub API、数据库查询、Slack 集成 |
我的使用建议:
- Skills:当你需要 Claude 遵循特定程序、使用领域知识或重复执行脚本时
- Sub-Agents:当你需要并行工作、委托复杂研究或隔离任务时
- MCP:当你需要与外部系统、API 交互时
从我个人的使用体验来看,Skills 是扩展 Claude 能力的最简单方式,不需要什么外部基础设施——这让它成为打包团队知识工作流程的理想选择。
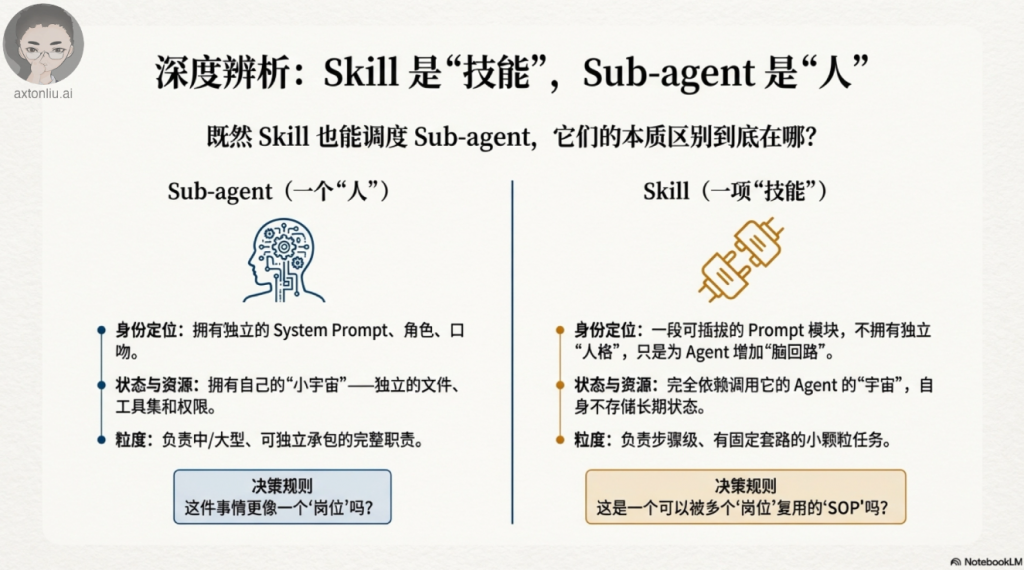
核心设计原则
在开始实现之前,先理解这三个区分有效 Skills 与臃肿 Skills 的原则。
原则1:简洁至上
上下文窗口是公共资源。
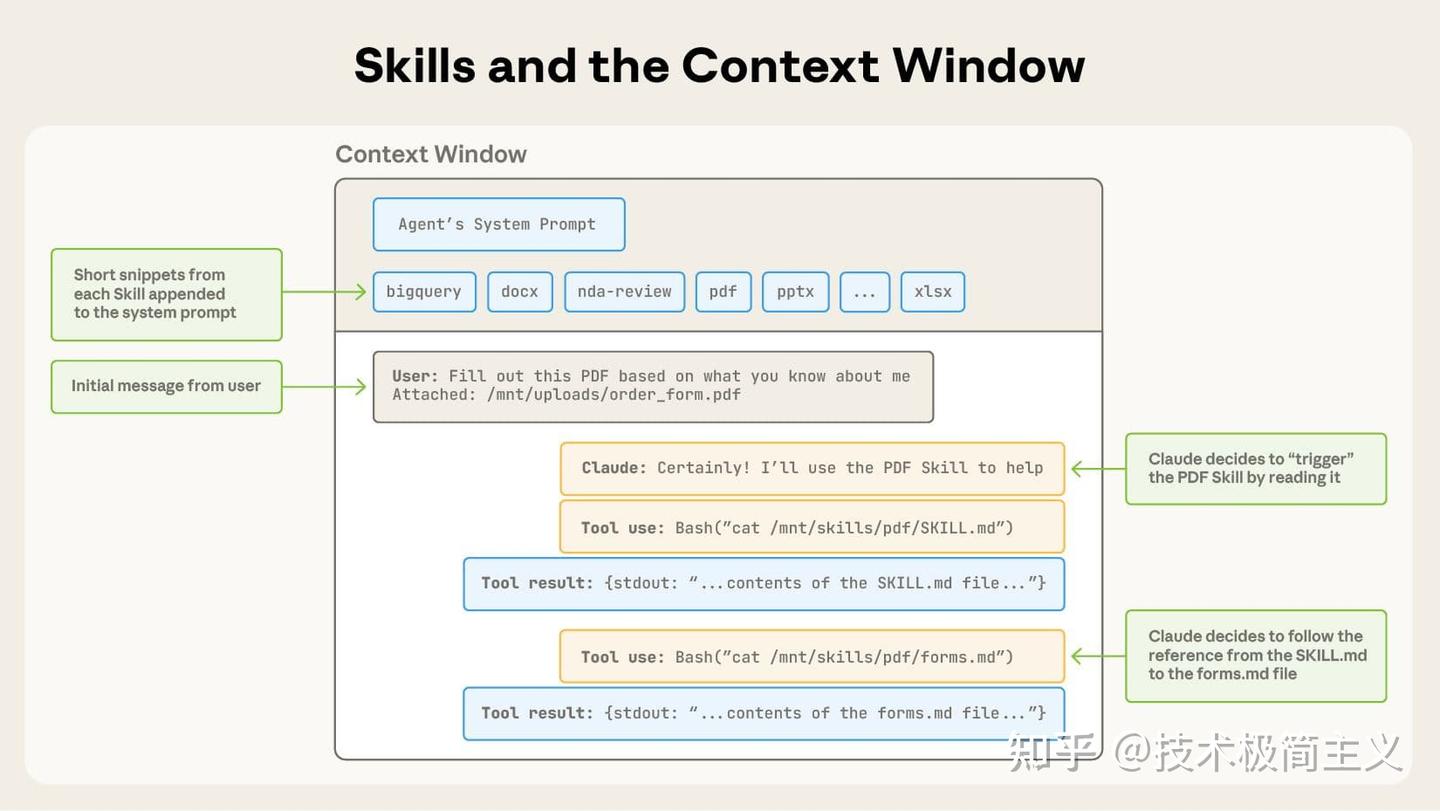
Skills 与 Claude 所使用的其他上下文是共享的:系统提示、对话历史、其他 Skills 的元数据,以及最终的用户请求,都会一并纳入。
默认假设:Claude 已经很聪明了。 仅提供 Claude 缺失的上下文信息。
对每一条信息都要保持怀疑态度:
- 「Claude 真的需要这个解释吗?」
- 「这个段落值得花费 token 吗?」
专业技巧:
优先使用简洁示例,而非冗长说明。精心设计的示例比整段描述传达更多信息,同时消耗更少 token。
原则2:设定合适的自由度
确保示例和说明的具体性与任务的脆弱性及变异性相匹配:
| 自由度级别 | 何时使用 | 实现方式 |
|---|---|---|
| 高 | 多种有效方法,依赖上下文的决策 | 基于文本的指令 |
| 中 | 存在首选模式,允许一些变化 | 伪代码或参数化脚本 |
| 低 | 脆弱操作,一致性至关重要 | 特定脚本,少量参数 |
核心洞察:
把 Claude 想象成正在探索一条路径:两侧是悬崖的狭窄桥梁,需要明确而严格的护栏(低自由度);而开阔的田野,则允许多种前进路线(高自由度)。你的 Skills 指导,应当与所处的地形相匹配。
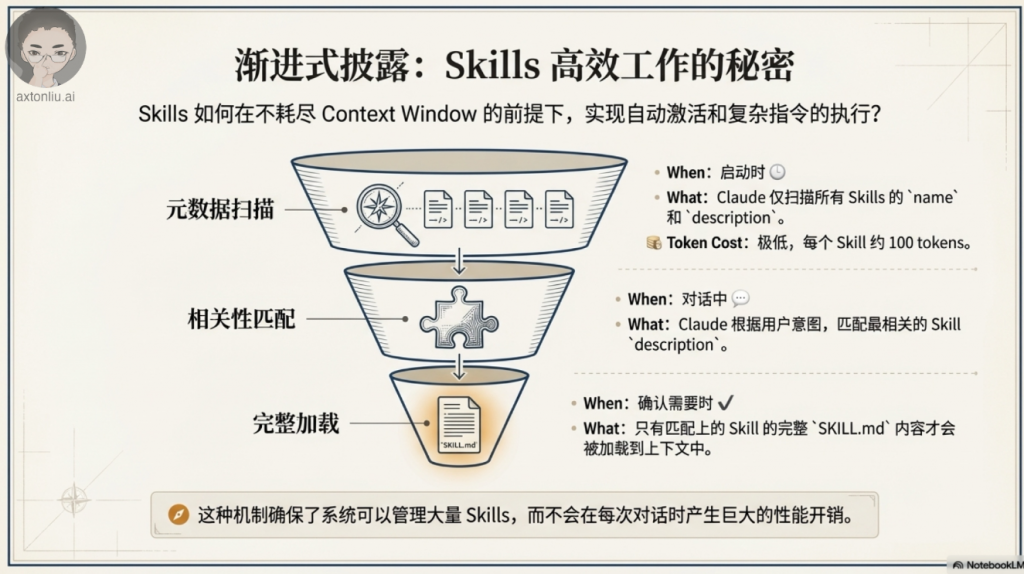
原则3:渐进式披露
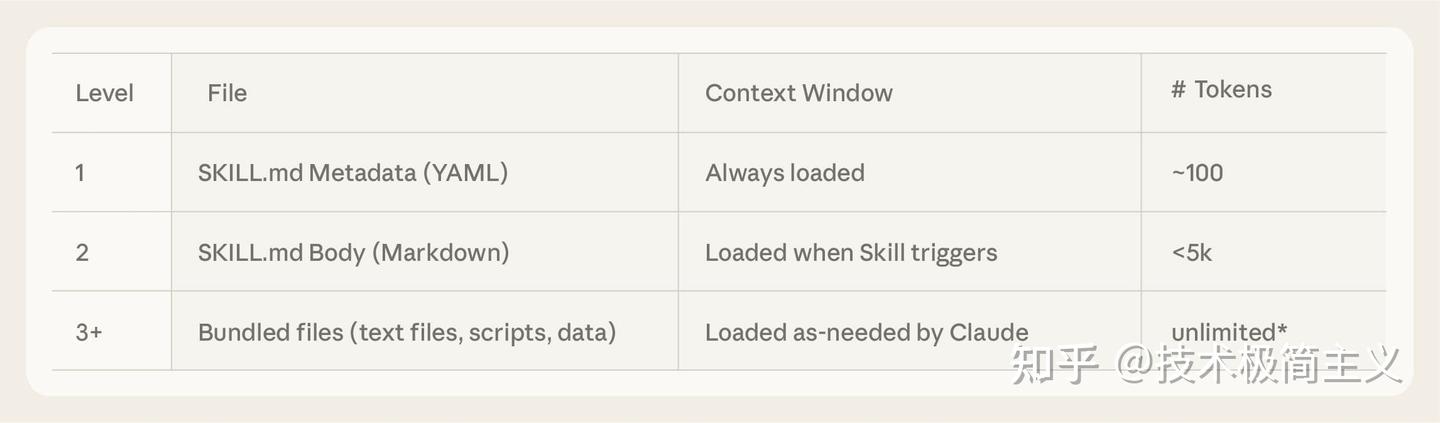
Skills 使用三级加载系统来高效管理上下文:
第一级 – 元数据(始终加载)
- YAML 前置元数据中的名称和描述
- 每个 Skill 约 100 token
- 支持发现而不消耗上下文
第二级 – SKILL.md 主体(触发时加载)
- 主要指令和程序
- 目标控制在 500 行 / 5k token 以下
- 当 Claude 判定 Skill 相关时加载
第三级 – 打包资源(按需加载)
- 脚本、参考资料、资产
- 无限容量
- 脚本可以在不加载到上下文的情况下执行
注意:保持 SKILL.md 精简,最好不要超过 500 行。如果快到上限,可以把内容拆到单独的参考文件,这样既防止上下文膨胀,也不影响功能。
技能文件结构

基础结构
每个 Skill 都遵循以下目录结构:
skill-name/
├── SKILL.md (必需)
│ ├── YAML 前置元数据 (必需)
│ │ ├── name: (必需)
│ │ └── description: (必需)
│ └── Markdown 指令 (必需)
└── 打包资源 (可选)
├── scripts/ - 可执行代码
├── references/ - 上下文文档
└── assets/ - 输出文件(模板等)SKILL.md 格式
---
name: your-skill-name
description: 这个技能做什么以及何时使用。包括触发上下文、文件类型、任务类型和用户可能提及的关键词。
---
# Your Skill Name
[指令部分]
Claude 的清晰、分步指导。
[示例部分]
具体的输入/输出示例。前置元数据要求
| 字段 | 必需 | 约束 |
|---|---|---|
| name | 是 | 小写,允许连字符,最多 64 字符 |
| description | 是 | 最多 1024 字符,必须包含 WHAT 和 WHEN |
核心要点:描述字段是技能触发的关键,告诉 Claude 技能能做什么以及什么时候使用。主体内容只会在触发后加载,所以「何时使用」不要放在主体里。
打包资源

Scripts (scripts/)
可执行代码(Python/Bash/等),用于需要确定性可靠性的任务。
何时包含:
- 相同代码被重复编写
- 需要确定性可靠性
- 容易出错的复杂操作
好处:
- Token 高效
- 确定性结果
- 可以在不加载到上下文的情况下执行
#!/usr/bin/env python3
"""按指定度数旋转 PDF 页面。"""
import argparse
from pypdf import PdfReader, PdfWriter
def rotate_pdf(input_path, output_path, degrees):
reader = PdfReader(input_path)
writer = PdfWriter()
for page in reader.pages:
page.rotate(degrees)
writer.add_page(page)
with open(output_path, "wb") as f:
writer.write(f)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("input", help="输入 PDF 路径")
parser.add_argument("output", help="输出 PDF 路径")
parser.add_argument("--degrees", type=int, default=90)
args = parser.parse_args()
rotate_pdf(args.input, args.output, args.degrees)References (references/)
根据需要加载到上下文中的文档。
何时包含:
- 数据库架构
- API 文档
- 领域知识
- 公司政策
- 详细工作流程指南
最佳实践:如果文件较大(>10k 字),在 SKILL.md 中包含 grep 搜索模式。
专业技巧:
信息应该存在于 SKILL.md 或 references 中——不能同时存在。
仅在 SKILL.md 中保留基本程序指令;将详细参考资料移到 references 文件。
这保持 SKILL.md 精简同时使信息可发现。
Assets (assets/)
不加载到上下文但在输出中使用的文件。
何时包含:
- 模板(PowerPoint、文档)
- 品牌资产(徽标、图像)
- 样板代码
- 字体
好处:将输出资源与文档分离,使 Claude 能够使用文件而不加载它们。
不应包含的内容
Skill 应只包含基本文件。不要创建:
- README.md
- INSTALLATION_GUIDE.md
- QUICK_REFERENCE.md
- CHANGELOG.md
Skill 应只包含 AI 代理完成工作所需的内容——而不是关于创建、设置程序或面向用户文档的辅助上下文。
六步创建流程
步骤1:通过具体示例理解
要创建有效的 Skill,收集它将如何使用的具体示例。询问如下问题:
- 「这个技能应该支持什么功能?」
- 「你能举一个这个技能如何使用的例子吗?」
- 「用户会说什来触发这个技能?」
核心洞察:
不要用问题让用户不知所措。从最重要的开始,根据需要跟进。当你对技能应该支持的功能有清晰感知时结束。
图像编辑器技能的示例:
- 用户可能会说:「从这张图像中去除红眼」
- 用户可能会说:「将这张图像旋转 90 度」
- 用户可能会说:「将这张照片调整为 800×600」
步骤2:规划可复用内容
通过以下方式分析每个示例:
- 考虑如何从头开始执行示例
- 识别在重复执行时会有帮助的脚本、参考资料和资产
示例分析:
| 技能 | 示例查询 | 分析 | 所需资源 |
|---|---|---|---|
| pdf-editor | 「旋转这个 PDF」 | 每次都需要重写相同代码 | scripts/rotate_pdf.py |
| frontend-builder | 「给我构建一个待办应用」 | 每次都需要相同样板 | assets/hello-world/ 模板 |
| bigquery | 「有多少用户登录?」 | 需要重新发现架构 | references/schema.md |
步骤3:初始化 Skill
从头创建时,使用 Anthropic 的初始化脚本:
scripts/init_skill.py <skill-name> --path <output-directory>脚本会:
- 在指定路径创建技能目录
- 生成带有正确前置元数据的 SKILL.md 模板
- 创建示例资源目录
- 添加可以自定义或删除的示例文件
手动初始化替代方案:
mkdir -p my-skill/{scripts,references,assets}
touch my-skill/SKILL.md步骤4:编辑 Skill
记住:你正在为另一个 Claude 实例创建这个技能。包含有益且非显而易见的信息。
从可复用内容开始
实现在步骤 2 中识别的脚本、参考资料和资产。
重要提示:通过实际运行来测试所有脚本。如果有许多类似脚本,测试代表性样本以确保它们工作。
删除技能不需要的任何示例文件。
编写 SKILL.md
写作指南:始终使用祈使/不定式形式。
前置元数据示例:
---
name: docx-processor
description: 综合文档创建、编辑和分析,支持跟踪更改、评论、格式保留和文本提取。当 Claude 需要处理专业文档(.docx 文件)时使用:(1) 创建新文档,(2) 修改或编辑内容,(3) 处理跟踪更改,(4) 添加评论,或任何其他文档任务。
---主体结构:
# Skill Name
## Getting Started
[基本的第一步]
## Core Workflows
[分步程序]
## Extended Capabilities
- **Feature A**: See [FEATURE_A.md](references/feature_a.md)
- **Feature B**: See [FEATURE_B.md](references/feature_b.md)
## Examples
[具体的输入/输出对]步骤5:打包 Skill
开发完成后,打包成可分发的 .skill 文件:
scripts/package_skill.py <path/to/skill-folder>可选输出目录:
scripts/package_skill.py <path/to/skill-folder> ./dist打包脚本会:
- 自动验证技能:
- YAML 前置元数据格式和必需字段
- 命名约定和目录结构
- 描述完整性和质量
- 文件组织和资源引用
- 打包如果验证通过,创建
.skill文件(zip 格式)
如果验证失败,修复错误并再次运行。
步骤6:基于使用迭代
通过实际使用改进技能:
- 在真实任务上使用技能
- 识别瓶颈与低效环节
- 识别 SKILL.md 或资源需要的更新
- 实现更改并再次测试
专业技巧:
即时反馈,即刻迭代。在记忆最清晰时,捕获每一个改进契机。
高级模式与技巧
这一节涵盖有效组织和构建技能的高级模式。
渐进式披露模式
模式1:高级指南与参考资料
# PDF 处理
## Quickstart
使用 pdfplumber 提取文本:
[代码示例]
## Additional Capabilities
- **表单填写**: See [FORMS.md](references/forms.md)
- **API 参考**: See [REFERENCE.md](references/reference.md)
- **示例**: See [EXAMPLES.md](references/examples.md)Claude 仅在需要时加载参考文件。
模式2:领域特定组织
对于支持多个领域的技能,按领域组织:
bigquery-skill/
├── SKILL.md (概览和导航)
└── references/
├── finance.md (收入、计费指标)
├── sales.md (机会、渠道)
├── product.md (API 使用、功能)
└── marketing.md (活动、归因)当用户询问销售指标时,Claude 只读取 sales.md。
模式3:框架/变体组织
对于支持多个框架的技能:
cloud-deploy/
├── SKILL.md (工作流程 + 提供商选择)
└── references/
├── aws.md (AWS 部署模式)
├── gcp.md (GCP 部署模式)
└── azure.md (Azure 部署模式)当用户选择 AWS 时,Claude 只读取 aws.md。
模式4:条件细节
显示基本内容,并提供指向高级内容的链接:
# DOCX 处理
## 创建文档
使用 docx-js 创建新文档。See [DOCX-JS.md](references/docx-js.md)。
## 编辑文档
对于简单编辑,直接修改 XML。
**对于跟踪更改**: See [REDLINING.md](references/redlining.md)
**对于 OOXML 详情**: See [OOXML.md](references/ooxml.md)重要指南
- 避免深度嵌套引用 – 引用不要嵌套太深,保持只距 SKILL.md 一层即可
- 结构化较长文件 – 文件太长(超过 100 行)时,在顶部加一个目录,让阅读更方便
工作流模式
顺序工作流
处理复杂、多步的任务时,把工作分成几步,并在开始时提供一个整体概览:
## 填写 PDF 表单
此过程涉及 5 个步骤:
1. 分析表单结构
2. 创建字段映射
3. 验证映射
4. 填写表单
5. 验证输出
### 步骤 1: 分析表单结构
[详细指令]
### 步骤 2: 创建字段映射
[详细指令]
...条件工作流
对于有决策分支的任务:
## 文档处理
首先,确定任务类型:
- **创建新文档**: 转到 A 节
- **编辑现有文档**: 转到 B 节
- **转换格式**: 转到 C 节
### A 节: 创建新文档
[创建的具体步骤]
### B 节: 编辑现有文档
[编辑的具体步骤]
...输出模式
模板模式(严格)
对于需要精确性的场景:
## 报告格式
始终使用这个确切结构:
### 执行摘要
[2-3 句总结发现]
### 主要发现
1. [有支持数据的发现]
2. [有支持数据的发现]
### 建议
- [可操作建议]
- [可操作建议]模板模式(灵活)
当适应增加价值时:
## 分析格式
使用这个建议结构,根据需要调整:
- **概览**: 上下文和范围
- **分析**: 关键观察
- **洞察**: 模式和含义
- **下一步**: 推荐行动
在部分深度和细节上使用最佳判断。示例模式
对于风格一致性,包含输入/输出对:
## 提交消息示例
**输入**: 添加用户认证
**输出**: feat(auth): 实现基于 JWT 的用户认证
**输入**: 修复支付处理中的错误
**输出**: fix(payments): 解决结账流程中的竞态条件
**输入**: 更新依赖
**输出**: chore(deps): 将 axios 升级到 1.6.0,更新 lodash核心洞察:
示例比单独的描述更能帮助 Claude 明白你希望的风格和细节。如果你希望输出保持一致的风格,就值得花时间准备好示例。
实战示例解析
案例1: API 文档技能
---
name: api-documenter
description: 从代码生成和维护 API 文档。用于记录 REST API、生成 OpenAPI 规范、创建 SDK 文档或维护 API 参考指南。在涉及 API 文档、端点文档或 Swagger/OpenAPI 的请求上触发。
---
# API 文档技能
从源代码和规范生成全面的 API 文档。
## 用法
对于 OpenAPI 生成:
python scripts/generate_openapi.py --input ./routes --output api-spec.yaml
## 文档模板
### 端点文档
## [METHOD] /path/to/endpoint
**描述**: 此端点做什么
**认证**: 必需/可选
**参数**:
| 名称 | 类型 | 必需 | 描述 |
|------|------|----------|-------------|
**响应**: { "example": "response" }
## 额外功能
- **SDK 生成**: See [SDK.md](references/sdk.md)
- **版本控制**: See [VERSIONING.md](references/versioning.md)案例2: 数据库迁移技能
---
name: db-migrator
description: 为 PostgreSQL、MySQL 和 SQLite 创建和管理数据库迁移。用于生成迁移、处理架构更改、管理回滚或使用像 Prisma 或 TypeORM 这样的 ORM。在迁移请求、架构更改或数据库版本控制上触发。
---
# 数据库迁移技能
创建安全、可逆的数据库迁移。
## 工作流程
1. 分析当前架构
2. 确定所需更改
3. 生成迁移文件
4. 验证迁移安全性
5. 提供回滚策略
## 迁移安全检查
在任何破坏性操作之前:
- 验证没有数据丢失
- 检查外键约束
- 估计锁定持续时间
- 准备回滚脚本
## 框架特定指南
- **Prisma**: See [PRISMA.md](references/prisma.md)
- **TypeORM**: See [TYPEORM.md](references/typeorm.md)
- **Raw SQL**: See [RAW_SQL.md](references/raw_sql.md)案例3: 代码审查技能
---
name: code-reviewer
description: 执行全面代码审查,重点关注安全性、性能和可维护性。适用于拉取请求审查、代码质量审计、漏洞检查以及确保最佳实践。该技能在审查请求、PR 分析或安全审计时触发。
---
# 代码审查技能
系统性代码审查,专注于安全性、性能和质量。
## 审查清单
### 安全性(关键)
- [ ] SQL 注入漏洞
- [ ] XSS 攻击向量
- [ ] 硬编码秘密/凭据
- [ ] 认证绕过风险
- [ ] 输入验证缺口
### 性能
- [ ] N+1 查询模式
- [ ] 内存泄漏潜力
- [ ] 低效算法
- [ ] 缺少索引
### 质量
- [ ] DRY 违规
- [ ] 死代码
- [ ] 复杂函数(>50 行)
- [ ] 缺少错误处理
## 输出格式
[严重级别] 问题概览
定位:文件路径及行号
现象:具体错误详情
影响:对业务或功能的危害
对策:解决方案或修复步骤
## 语言特定指南
- **JavaScript/TypeScript**: See [JS.md](references/js.md)
- **Python**: See [PYTHON.md](references/python.md)
- **Go**: See [GO.md](references/go.md)生产环境部署指南
存储和共享技能
遇到问题时,可参考以下存储方式来组织你的技能。
个人技能
在所有项目中可用:
~/.claude/skills/skill-name/SKILL.md项目技能
通过 git 与团队共享:
.claude/skills/skill-name/SKILL.md从市场安装
将 Anthropic 技能仓库注册为插件:
/plugin marketplace add anthropics/skills然后浏览并安装特定技能集:
/plugin install document-skills@anthropic-agent-skills安装好后,只要提到相关任务,技能就会自己激活。
生产考虑

验证清单
在部署技能之前:
- [ ] YAML 前置元数据有效
- [ ] 描述包含 what 和 when
- [ ] 所有脚本测试并工作
- [ ] 参考资料从 SKILL.md 正确链接
- [ ] SKILL.md 和参考资料之间没有重复信息
- [ ] SKILL.md 总计少于 500 行
- [ ] 没有多余的文档文件
安全最佳实践
注意:在运行技能前,一定先检查一遍,尤其是从外部获取的。看看有没有意外联网、修改文件或泄露数据的情况。
环境变量:
- 不要在技能中硬编码 API 密钥或秘密
- 引用环境变量:
$API_KEY - 在 SKILL.md 中记录所需变量
工具限制:
- 在适当时使用前置元数据中的
allowed-tools - 对于敏感操作限制为只读工具
性能优化
Token 效率:
- 最小化 SKILL.md 大小
- 使用参考资料获取详细内容
- 提供示例而非解释
加载优化:
- 按领域组织参考资料
- 在大文件中包含目录
- 使用清晰的文件命名以便快速发现
常见问题
Q1:什么是 Claude Skill?
A:Skill 是一个模块化包,包含指令、脚本和资源,Claude 可以动态发现和加载它们。它将 Claude 从通用助手转变为特定任务的专业化智能体,为特定领域提供专业能力。
Q2:Claude 如何发现我的技能?
A:Claude 在启动时会读取技能的元数据(名称和描述)。当请求与描述匹配时,Claude 会加载完整的 SKILL.md 并遵循其指令。这被称为「渐进式披露」机制。
Q3:我应该在哪里存储我的技能?
A:个人技能放在 ~/.claude/skills/ 中,可在所有项目中使用。项目技能放在 .claude/skills/ 中,可以通过 git 与团队成员共享。
Q4:技能和斜杠命令有什么区别?
A:斜杠命令是用户调用的(/command),会立即执行。技能是由模型调用的——Claude 根据上下文自动发现并使用它们。技能更适合复杂的多步骤能力。
Q5:如何限制技能使用的工具?
A:在 YAML 前置元数据中添加 allowed-tools。例如:allowed-tools: Bash, Read, Grep 可以防止文件修改,同时允许读取操作。
Q6:description 字段应该包含什么内容?
A:包含技能做什么以及何时使用。添加触发上下文、文件类型、任务类型和用户可能提及的关键词。这是技能发现的主要机制。
Q7:SKILL.md 应该多长?
保持在 500 行以下。如果接近此限制,将内容拆分为参考文件。在 SKILL.md 中清晰地链接到它们,让 Claude 知道它们的存在。
Q8:技能是否可以包含可执行代码?
A:可以。将脚本放在 scripts/ 目录中。这些可以是 Python、Bash 或任何可执行文件。脚本提供确定性可靠性,可以在不加载到上下文的情况下执行。
Q9:如何调试不工作的技能?
A:检查 YAML 前置元数据是否有效,描述是否包含相关触发词,以及文件是否在正确的位置。询问 Claude「有哪些可用的技能?」来验证发现机制。
Q10:我可以和团队分享技能吗?
A:可以。将技能存储在项目的 .claude/skills/ 中并提交到 git。克隆仓库的团队成员会自动获得访问权限。
总结与展望
构建你的技能库
Claude Skills 改变了我们和 AI 助手的互动方式。你不必每次都重新输入知识,而是可以把专业知识打包成可重复使用的模块,让它随着时间不断增值。