故障复盘 – 2024.11.11 某宝崩了:系统消息库出现局部故障,我们对消息库内部架构剖析
今天双十一,网传某宝崩了,微博上已经讨论的沸沸扬扬,目测要上热搜了。去年的双十一第二天,某里云就出现了全球史诗级大故障。这次看来,都等不及双十一过去,就开始整活了。
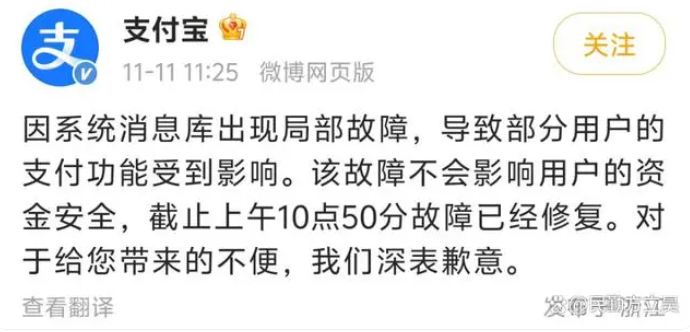
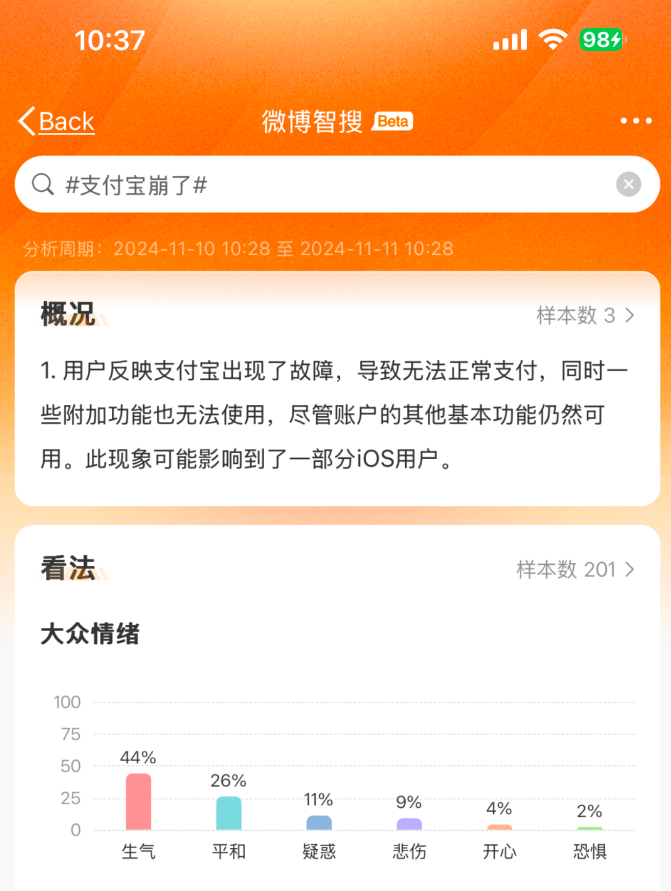

此次宕机事件,支付宝官方公布的故障原因为:系统消息库出现局部故障。这个系统消息库,就是一个存储系统内各类消息的数据库或数据存储及管理体系,具有消息的接收、存储、发送、检索等功能,以便系统各模块、组件或不同用户之间进行信息传递和交互。
这个消息库故障是如何发生的呢?在现代金融科技领域,数据是核心资产之一。支付宝作为一个庞大的支付平台,每天都会产生海量的数据。这些数据需要进行实时处理和分析,以确保平台的稳定运行。然而,随着用户数量的增加和技术的不断更新换代,数据的处理和存储变得越来越复杂。这就给支付宝的技术团队带来了巨大的挑战。
支付宝系统消息库的原理主要包括以下几个方面:
消息中间件:支付宝使用了一个名为Metamorphosis(MetaQ)的开源分布式消息中间件。Metamorphosis是一个高性能、高可用、可扩展的消息中间件,类似于LinkedIn的Kafka。它具有消息存储顺序写、吞吐量大、支持本地和XA事务等特性,适用于大吞吐量、顺序消息、广播和日志数据传输等场景。
数据库技术:支付宝主要使用MySQL、OceanBase、HBase和Redis等数据库技术。MySQL是其主要的关系型数据库,OceanBase是蚂蚁金服自主研发的分布式关系型数据库,HBase用于存储大规模结构化数据,Redis则用于缓存和快速数据访问。OceanBase是支付宝数据库架构的核心,具有强一致性、高可用性和线性扩展性,能够在大规模复杂业务场景下提供可靠的数据支持。
系统架构:支付宝的系统架构采用了单元化设计,将系统分为多个独立的单元,每个单元独立部署并服务特定的一群用户。这种设计有助于提高系统的可扩展性和可用性。支付宝在双11等大型活动日的支付TPS可以达到几十万级,这得益于其单元化架构设计。
高并发处理:在处理高并发请求时,支付宝通过优化数据库架构和采用高性能的消息中间件来确保系统的稳定性和高效性。例如,OceanBase支持高并发的交易处理,能够在秒级别内完成海量交易的处理和确认,确保每一笔交易的准确性和实时性。
故障处理:支付宝在面对系统故障时,能够迅速响应并恢复服务。例如,在2024年11月11日,支付宝在面对突发流量时,能够迅速处理并恢复正常运作,确保用户的支付功能不受影响
消息库的典型应用场景 支付通知
支付成功:支付系统生成支付成功的消息,消息队列将消息发送给通知系统,通知系统发送支付成功的通知给用户。
退款成功:退款系统生成退款成功的消息,消息队列将消息发送给通知系统,通知系统发送退款成功的通知给用户。
系统消息库的容灾和恢复策略主要包括以下方面:
一数据备份策略
1、全量备份:定期对系统消息库中的所有数据进行完整备份。这种备份方式能够提供最全面的数据副本,在系统遭受严重故障或数据丢失时,可以快速恢复到最近一次的全量备份状态。不过,全量备份可能会占用较多的存储空间和备份时间,通常适合在数据量相对较小或对数据恢复完整性要求极高的情况下使用,比如每周或每月进行一次全量备份。
2、增量备份:只备份自上一次备份以来发生变化的数据。与全量备份相比,增量备份的数据量较小,备份速度快,对系统资源的占用也较少。在恢复时,需要先恢复最近的一次全量备份,然后依次恢复后续的增量备份,才能将数据恢复到最新状态。适用于数据更新频繁的系统,可以每天或每小时进行一次增量备份。
3、差异备份:备份自上一次全量备份以来发生变化的数据。它结合了全量备份和增量备份的优点,在恢复时只需要先恢复最近的一次全量备份,再加上最近的一次差异备份即可。差异备份的频率可以根据数据变化的速度和对恢复时间的要求来确定,比如每隔几天进行一次差异备份。
二冗余技术策略
1、硬件冗余:采用冗余的硬件设备来保障系统消息库的可用性。例如,使用多台服务器组成集群,当其中一台服务器出现故障时,其他服务器可以自动接管其工作,确保系统的正常运行。同时,对于存储设备,可以使用磁盘阵列(RAID)技术,通过将数据存储在多个磁盘上,提高数据的可靠性和可用性。
2、软件冗余:在系统中部署冗余的软件组件,如冗余的数据库实例、消息队列等。当主软件组件出现故障时,冗余的组件可以立即接管工作,保证系统的不间断运行。此外,还可以使用负载均衡技术,将用户的请求分发到多个软件实例上,提高系统的处理能力和可用性。
3、数据冗余:除了在本地存储备份数据外,还可以将数据复制到多个异地的数据中心或云存储中,以防止因本地数据中心遭受灾难而导致数据丢失。数据冗余可以采用同步复制或异步复制的方式,同步复制可以保证数据的实时一致性,但对网络带宽和系统性能的要求较高;异步复制则可以在一定程度上降低对网络和系统的影响,但可能会存在数据延迟。
三灾难恢复计划策略
1、制定详细的恢复流程:明确在发生灾难时,系统消息库的恢复步骤和顺序,包括如何启动备份系统、如何恢复数据、如何重新启动应用程序等。恢复流程应该尽可能详细,并且要经过充分的测试和验证,确保在实际操作中能够顺利执行。
2、确定恢复时间目标(RTO)和恢复点目标(RPO):RTO 是指从灾难发生到系统恢复正常运行所需要的时间,RPO 是指在灾难发生时,系统能够容忍的数据丢失量。根据系统的重要性和业务需求,确定合理的 RTO 和 RPO 目标,并在容灾和恢复策略中加以考虑。例如,对于一些关键业务系统,可能要求 RTO 在数小时以内,RPO 为零,即不允许有数据丢失。
3、建立应急响应团队:组建专门的应急响应团队,负责在灾难发生时执行恢复计划。团队成员应包括系统管理员、数据库管理员、网络管理员、安全专家等,他们需要熟悉系统的架构和恢复流程,并且具备应对突发事件的能力。同时,要定期对应急响应团队进行培训和演练,提高团队的应急响应能力。
四监控与预警策略
1、实时监控系统状态:使用监控工具对系统消息库的运行状态进行实时监测,包括服务器的性能指标(如 CPU 利用率、内存使用率、磁盘 I/O 等)、数据库的连接数、消息队列的长度等。通过实时监控,可以及时发现系统的异常情况,并采取相应的措施进行处理。
2、设置预警机制:根据监控指标设置预警阈值,当系统的某些指标超过阈值时,自动发送预警信息给相关人员。预警信息可以通过短信、邮件、即时通讯等方式发送,以便相关人员能够及时了解系统的运行状况,并采取相应的措施。
五定期测试与演练策略
1、恢复测试:定期进行系统消息库的恢复测试,验证备份数据的完整性和可用性,以及恢复流程的有效性。恢复测试可以模拟各种灾难场景,如服务器故障、数据库损坏、网络中断等,通过实际的恢复操作,发现并解决可能存在的问题。
2、演练:组织定期的演练活动,让应急响应团队成员熟悉恢复流程和操作步骤,提高团队的协作能力和应急响应速度。演练可以采用桌面演练、模拟演练或实际演练等方式,根据实际情况选择合适的演练方式。
六安全策略
1、数据加密:对备份数据进行加密处理,防止数据在传输和存储过程中被窃取或篡改。加密算法应选择安全性高、性能好的算法,并定期更换密钥,以提高数据的安全性。
2、访问控制:严格控制对系统消息库和备份数据的访问权限,只有经过授权的人员才能访问和操作。可以采用身份认证、访问控制列表(ACL)等技术来实现访问控制,确保数据的安全性和保密性。
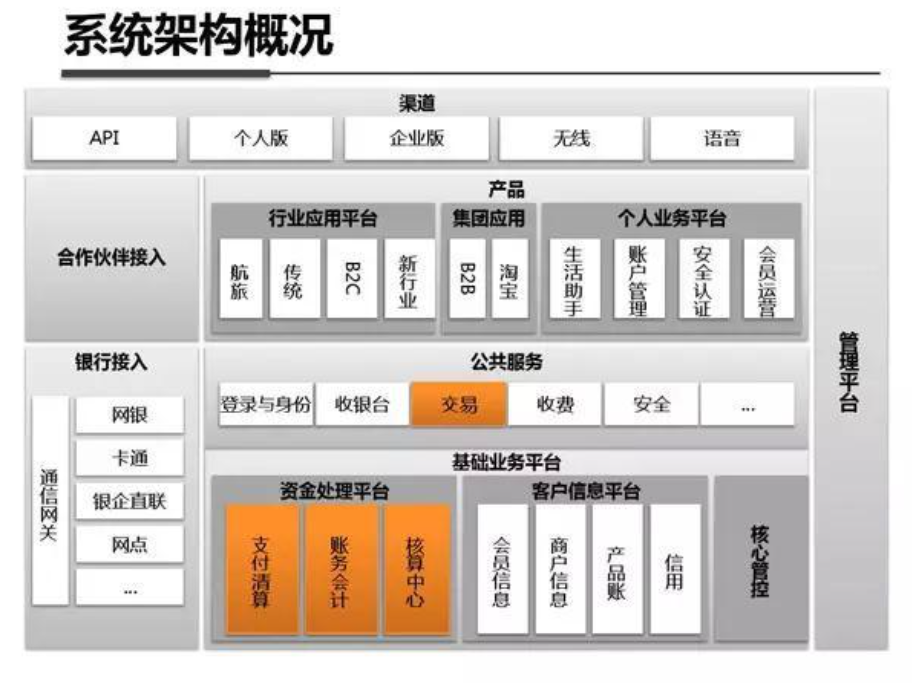
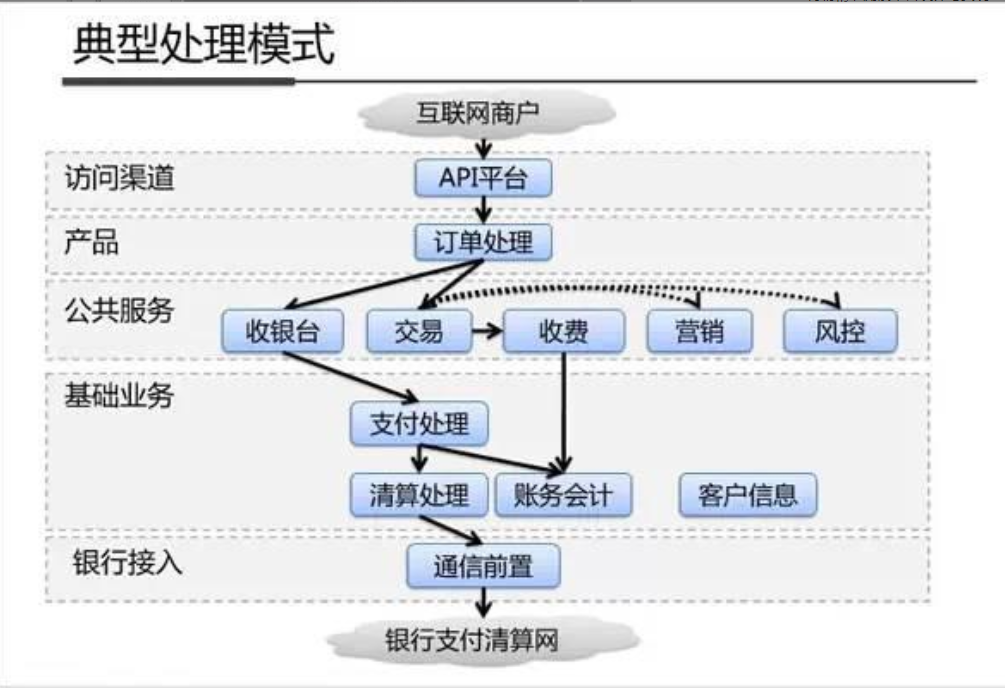
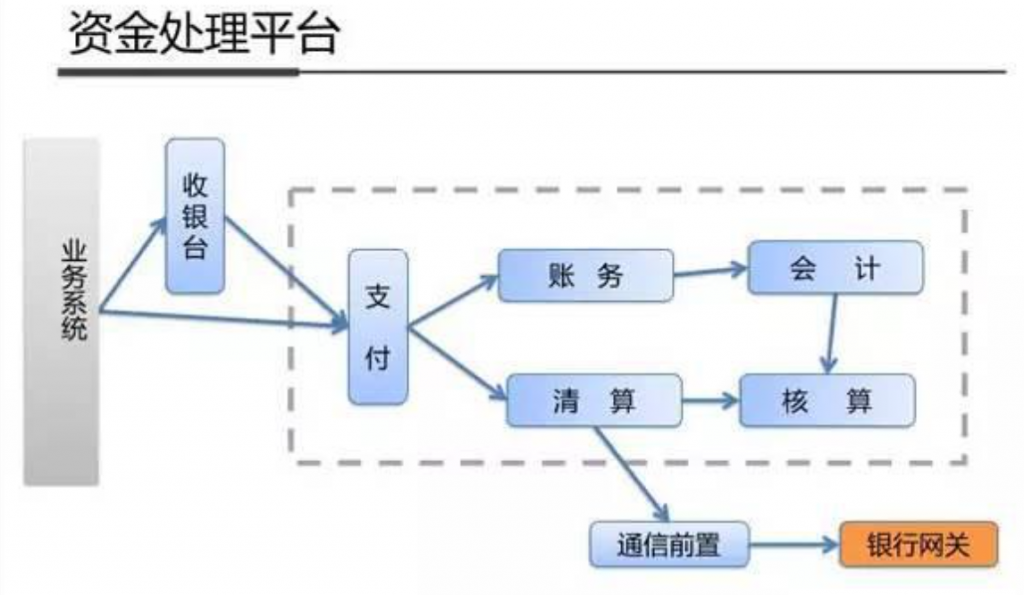
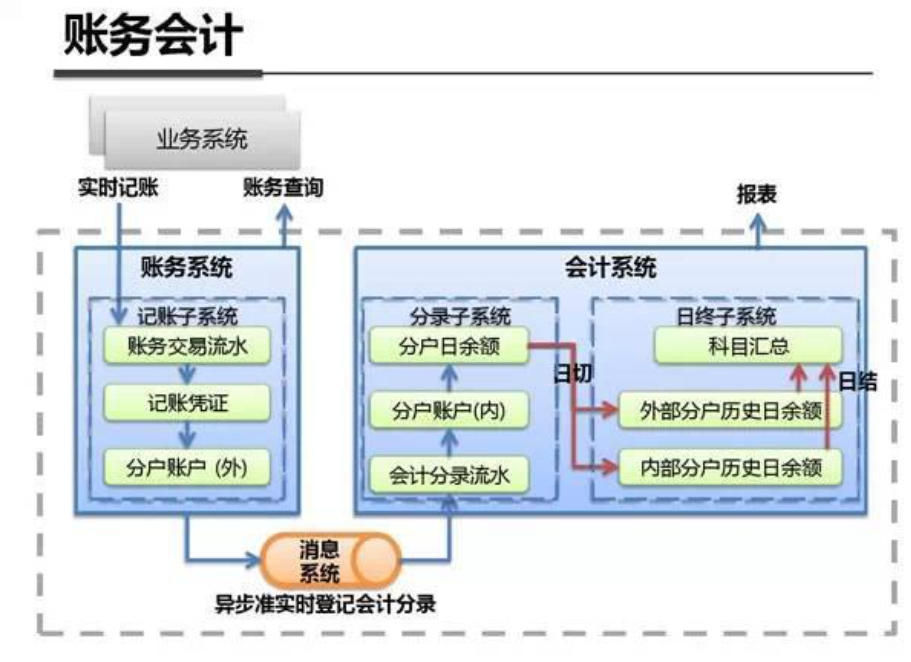
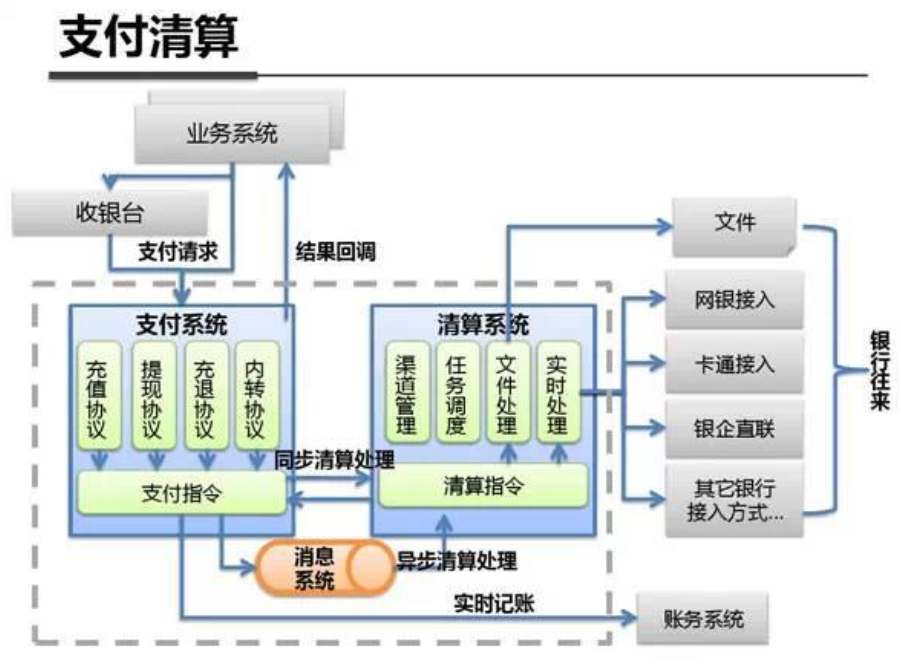
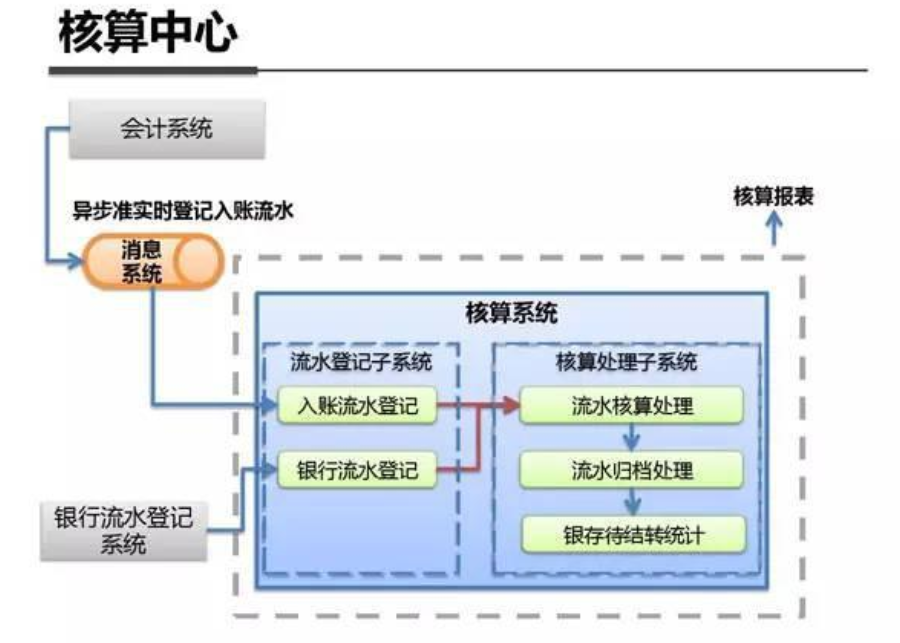
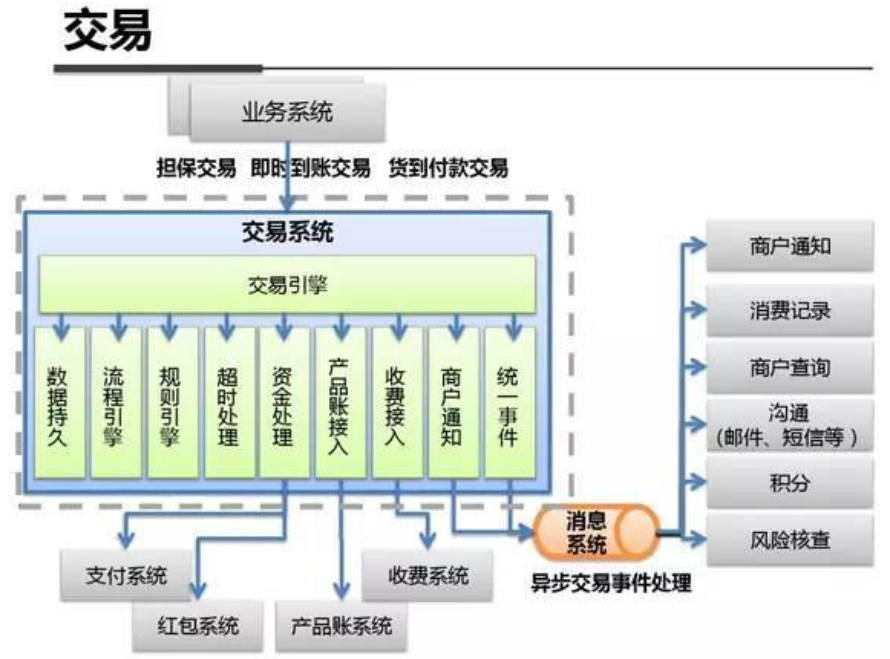
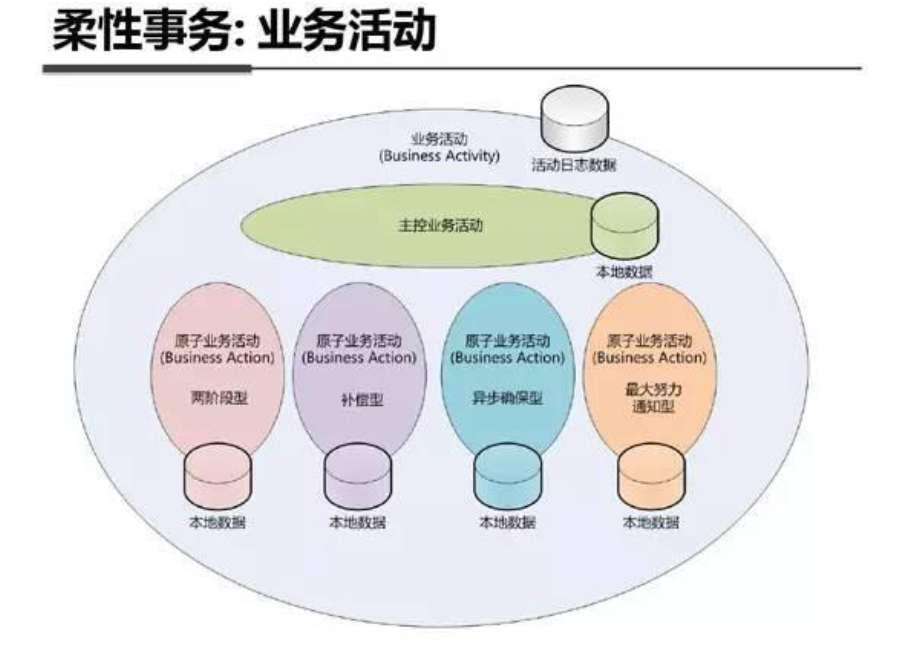
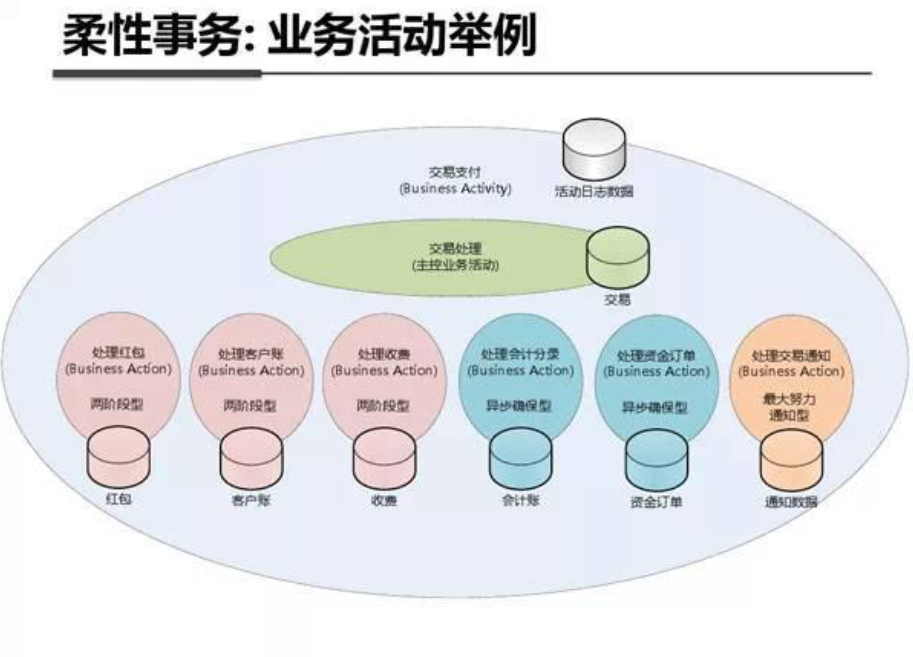
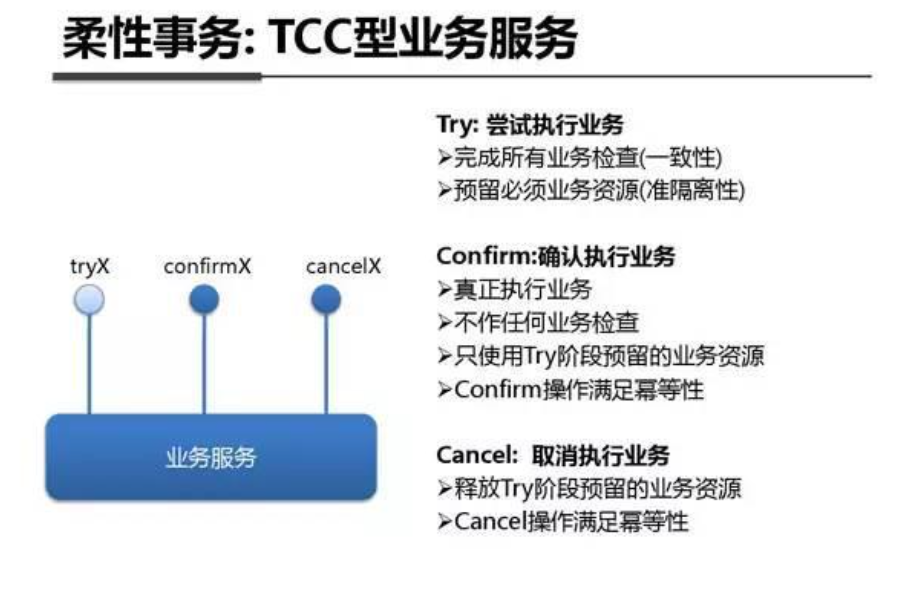
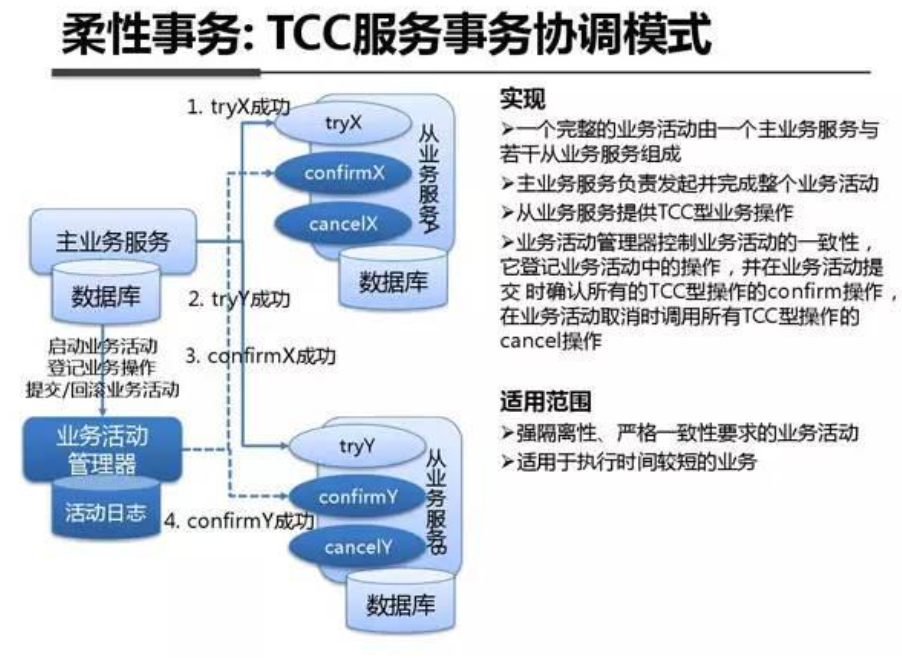
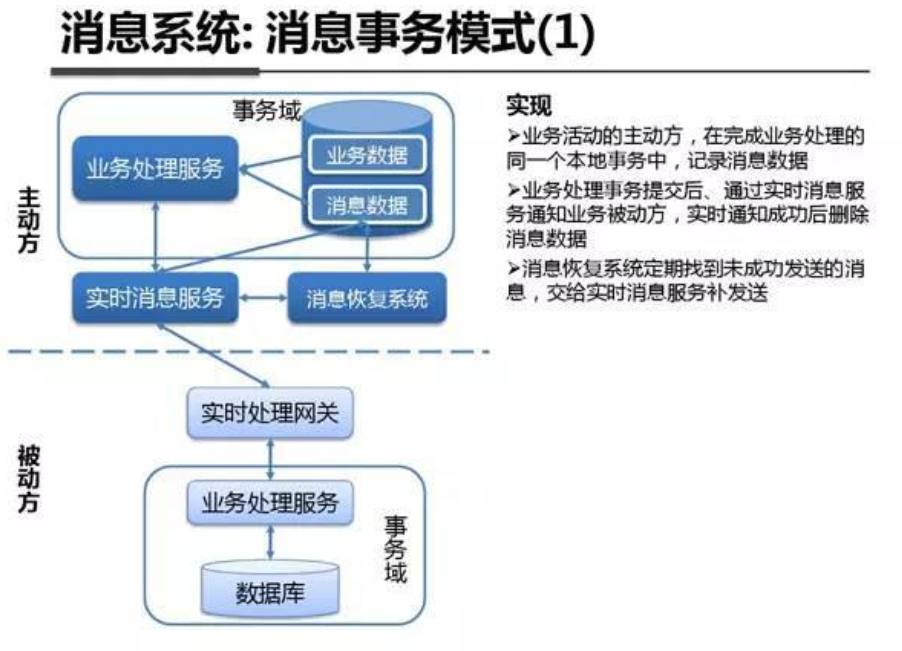
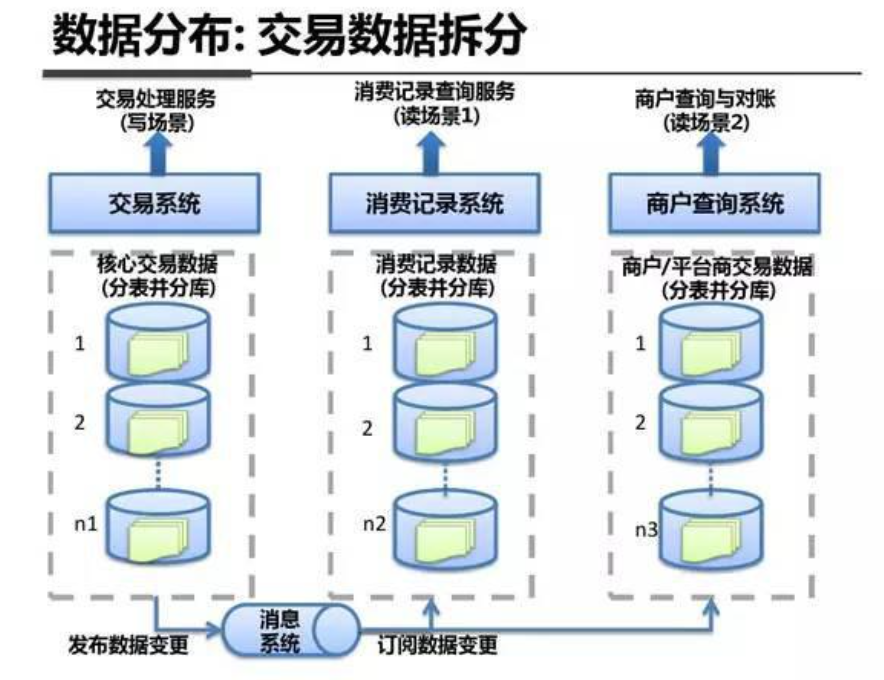
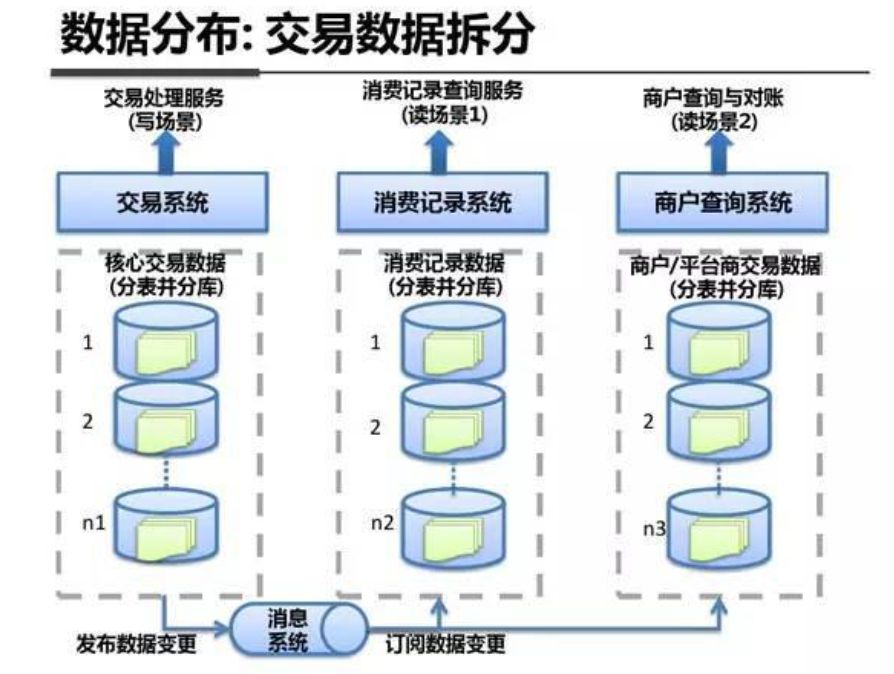
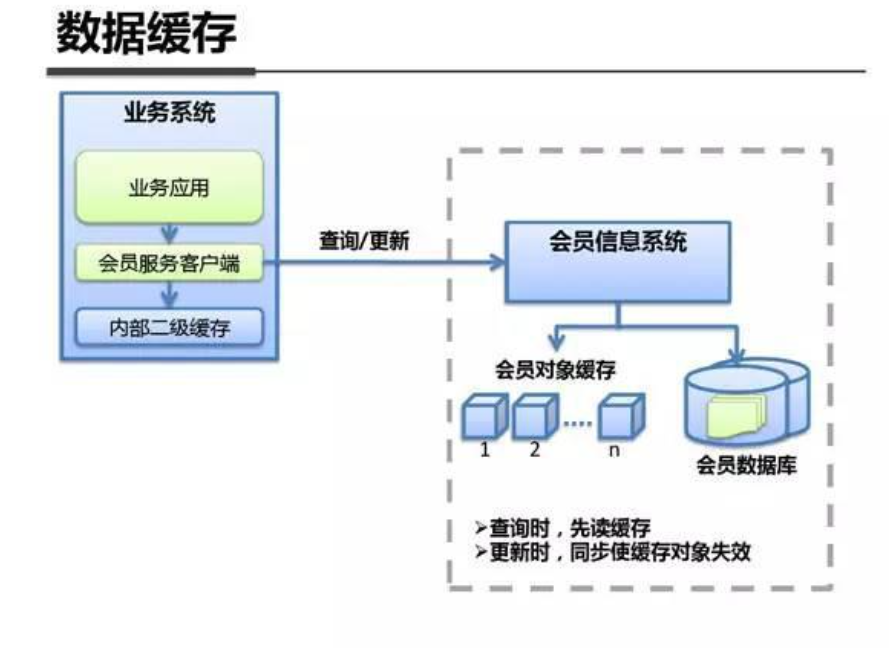
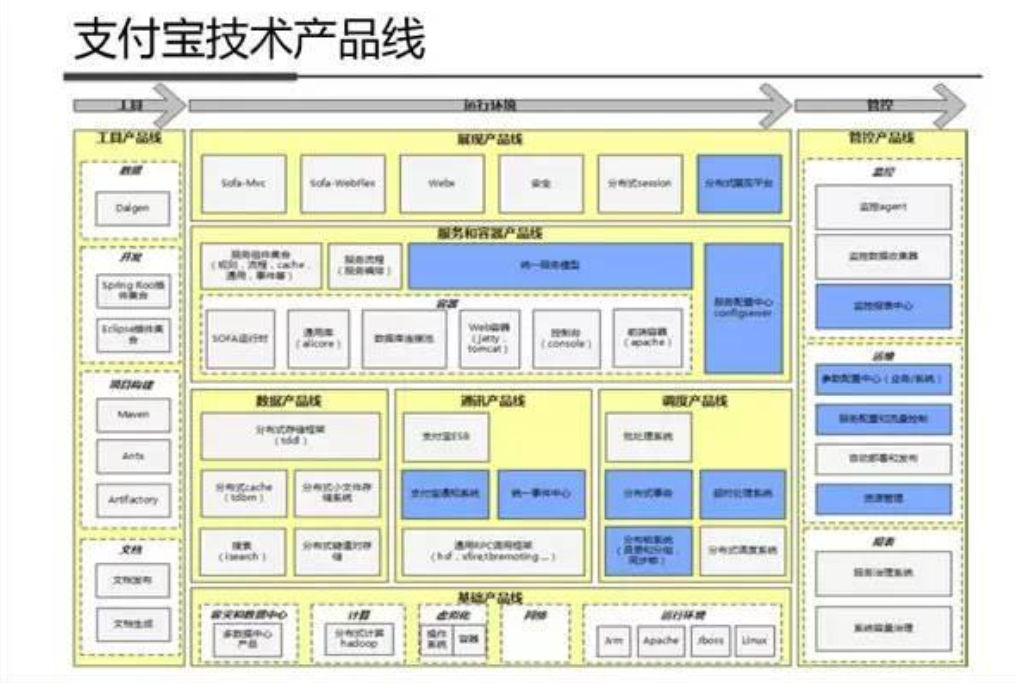
系统架构内部剖析