数字化运营基础技能 – python学习路线图经典版
关于Python数据分析,其实网上能够找到的学习资源很多,主要分为两类:一类是提供各种资源的推荐,比如书单、教程、以及学习的先后顺序;另一类是提供具体的学习内容,知识点或实际案例。
但很多繁琐而又杂乱的内容,除了给初学者增加理解和认识的噪音外,真正能够起到明确的方向指引导的,确实不多。以至于很多人一开始没有明确的方向就一头扎进去,学了很久却不知道自己到底在学什么,或者自己学了很久不知道能够做什么。
学习一门技术之前,你应该知道,你想要达成的目标是什么样的。也就是说,你想通过这门技术来解决哪些问题。你就可以知道要达成这样的目标,它的知识体系是怎么样的。更重要一点的是,每个部分是用来解决哪些问题,只有明确的目标导向,学习最有用的那部分知识,才能避免无效信息降低学习效率。
通过这些常见的数据分析场景,你就可以获得数据分析项目的基本流程。一般大致可以按“数据获取-数据存储与提取-数据预处理-数据建模与分析-数据报告”这样的步骤来实施一个数据分析项目。
按照这个流程,每个部分需要掌握的细分知识点如下:
接下来我们分别从每一个部分展开,讲讲具体应该学什么、怎么学,以及各个部分主要的知识点进行结构化地展示,并有针对性地推荐学习资源。
如何获取数据
我们分析的数据一般有内部数据和外部数据两种。
内部数据是在我们的业务运转中产生,比如常见的用户数据、产品数据、销售数据、内容数据等等。内部的数据相对来说更加完善、规整,我们经常要做的工作汇报、产品优化等分析数据一般来源于此。可以找公司的技术人员索要,或者自己去数据库提取。
当然,很多时候,我们需要利用外部的数据。比如进行市场调研,竞品分析,或者输出报告的时候,外部数据的分析是必不可少的,这也可以帮助我们得出更多的结论。如果你对Python感兴趣,欢迎加入我们【python学习交流】,免费领取学习资料和源码。
1. 公开数据源
UCI:加州大学欧文分校开放的经典数据集,真的很经典,被很多机器学习实验室采用。
http://archive.ics.uci.edu/ml/datasets.html
国家数据:数据来源于中国国家统计局,包含了我国经济民生等多个方面的数据。
http://data.stats.gov.cn/index.htm
CEIC:超过128个国家的经济数据,能够精确查找GDP、CPI、进出口以及国际利率等深度数据。
https://www.ceicdata.com/zh-hans
中国统计信息网:国家统计局的官方网站,汇集了海量的全国各级政府各年度的国民经济和社会发展统计信息。
政务数据网站:现在各个省都在很大程度上地开放政务数据,比如北京、上海、广东、贵州等等,都有专门的数据开放网站,搜索比如“北京政务数据开放”。
2. 网络爬虫
基于互联网爬取的数据,你可以对某个行业、某种人群进行分析。比如:
职位数据:拉勾、猎聘、51job、智联
金融数据:IT桔子、雪球网
房产数据:链家、安居客、58同城
零售数据:淘宝、京东、亚马逊
社交数据、微博、知乎、Twitter
影视数据:豆瓣、时光网、猫眼
……
在爬虫之前你需要先了解一些 Python 的基础知识:元素(列表、字典、元组等)、变量、循环、函数(菜鸟教程就很好)……
以及如何用成熟的 Python 库(urllib、BeautifulSoup、requests、scrapy)实现网页爬虫。
掌握基础的爬虫之后,你还需要一些高级技巧。比如正则表达式、模拟用户登录、使用代理、设置爬取频率、使用cookie等等,来应对不同网站的反爬虫限制。爬虫可以说是最为灵活、有效的数据获取方式,但学习成本相对来说也要高一些。开始建议先利用公开数据进行分析,后续有更多的数据需求,再上手爬虫。那个时候你已经掌握了Python基础,爬虫上手也会更轻松。
3. 其他数据获取方式
如果你暂时不会爬虫,但又有采集数据的需求,可以尝试各种采集软件,不需要编程知识也可以轻松爬取信息,比如火车头、八爪鱼等。很多数据竞赛网站也会公开不错的数据集,比如国外的Kaggle,国内的DataCastle、天池。这些数据都是真实的业务数据,且规模通常不小,可以经常去搜集和整理。
推荐数据汇总资源:
数据获取方式汇总 https://dwz.cn/Q44MsDkH
常用的数据获取方式如下:
数据存储与提取
数据库这个技能放在这里,是因为这是数据分析师的必备技能。大多数的企业,都会要求你有操作、管理数据库的基本技能,进行数据的提取和基本分析。SQL作为最经典的关系型数据库语言,为海量数据的存储与管理提供可能。MongoDB则是新崛起的非关系型数据库,掌握一种即可。
初学建议SQL。你需要掌握以下技能:
1.查询/提取特定情况下的数据:企业数据库里的数据一定是巨量而繁复的,你需要提取你想要的那一部分。
比如你可以根据你的需要提取2017年所有的销售数据、提取今年销量最大的50件商品的数据、提取上海、广东地区用户的消费数据……
2.数据库的增、删、改:这些是数据库最基本的操作,但只要用简单的命令就能够实现。
3.数据的分组聚合、建立多个表之间的联系:这个部分是数据库的进阶操作,多个表之间的关联。
在你处理多维度、多个数据集的时候非常有用,这也让你可以去处理更复杂的数据。
数据库听起来很可怕,但其实满足数据分析的那部分技能不要太简单。当然,还是建议你找一个数据集来实际操作一下,哪怕是最基础的查询、提取等操作。
推荐数据库教程:
SQL-菜鸟教程 https://dwz.cn/a042MLdz
MongoDB-菜鸟教程 https://dwz.cn/sJFhRzj1
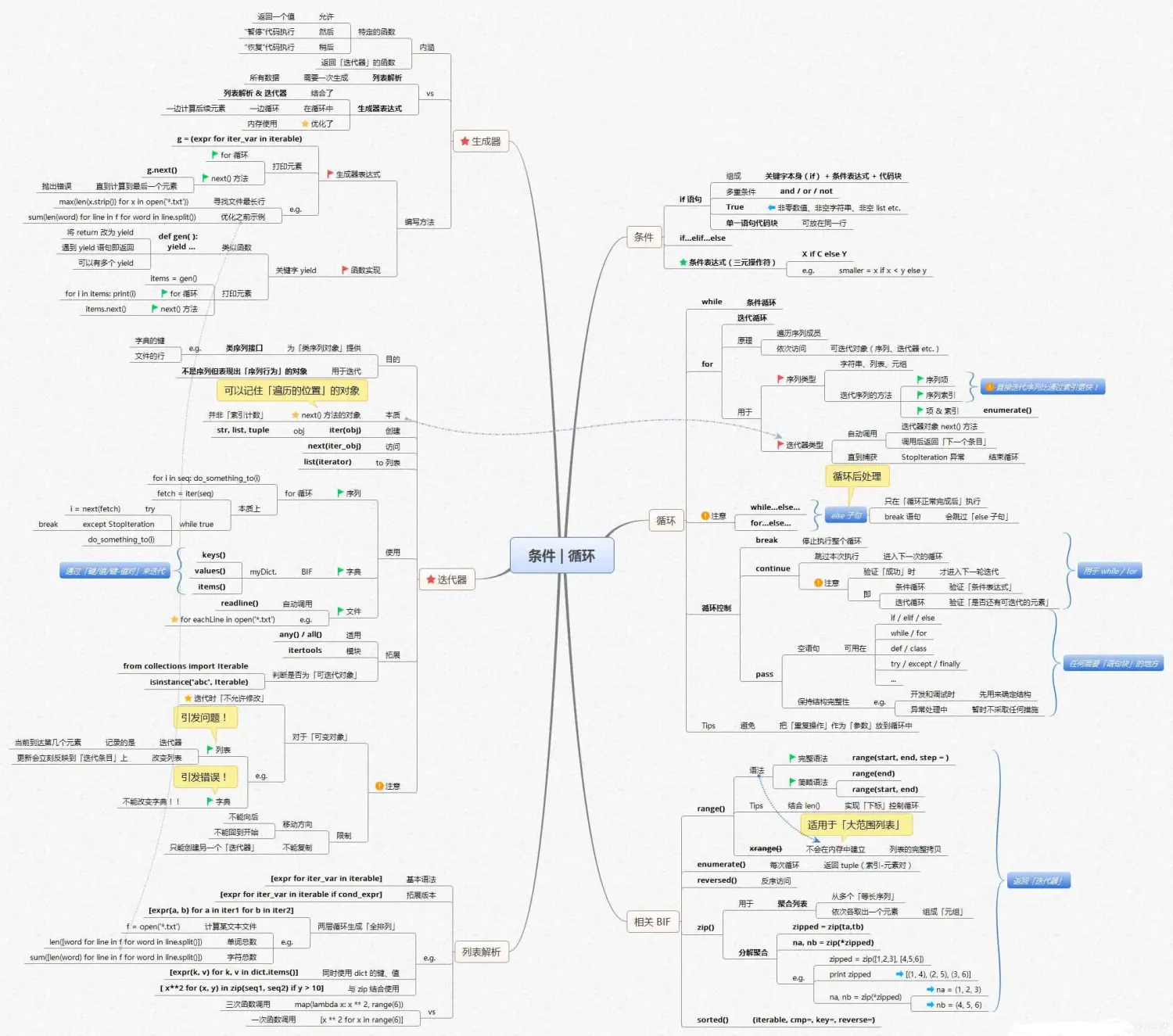
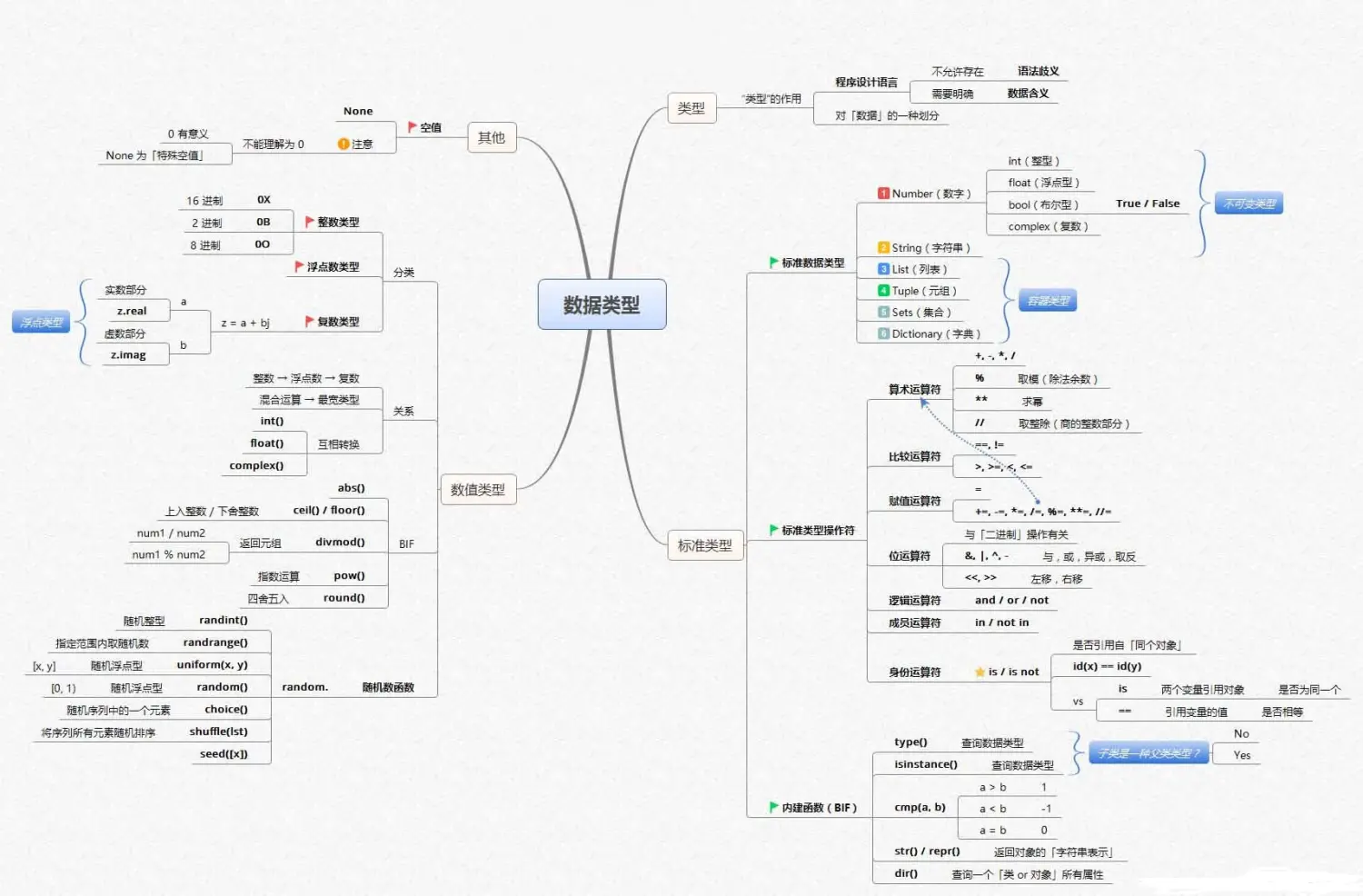
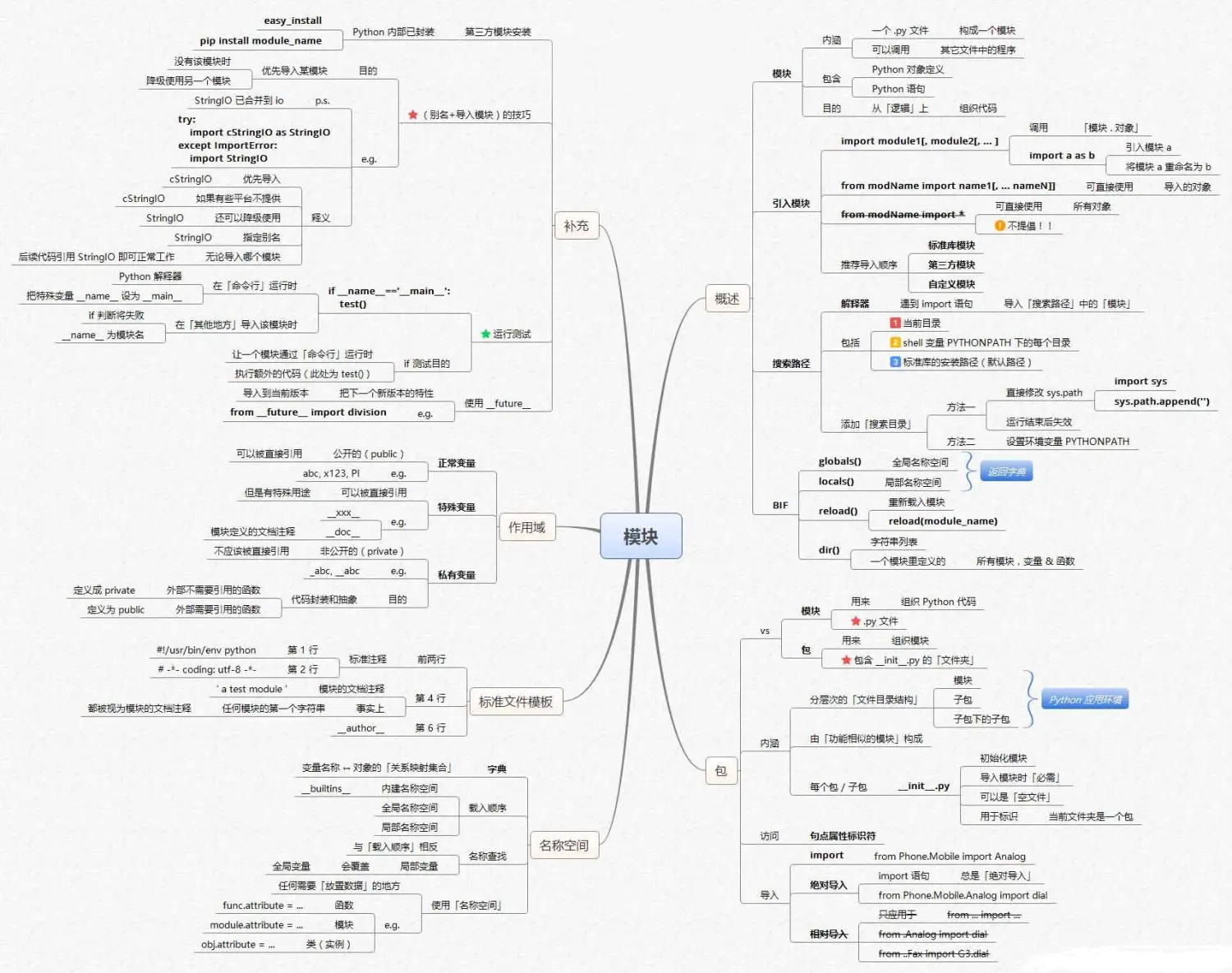

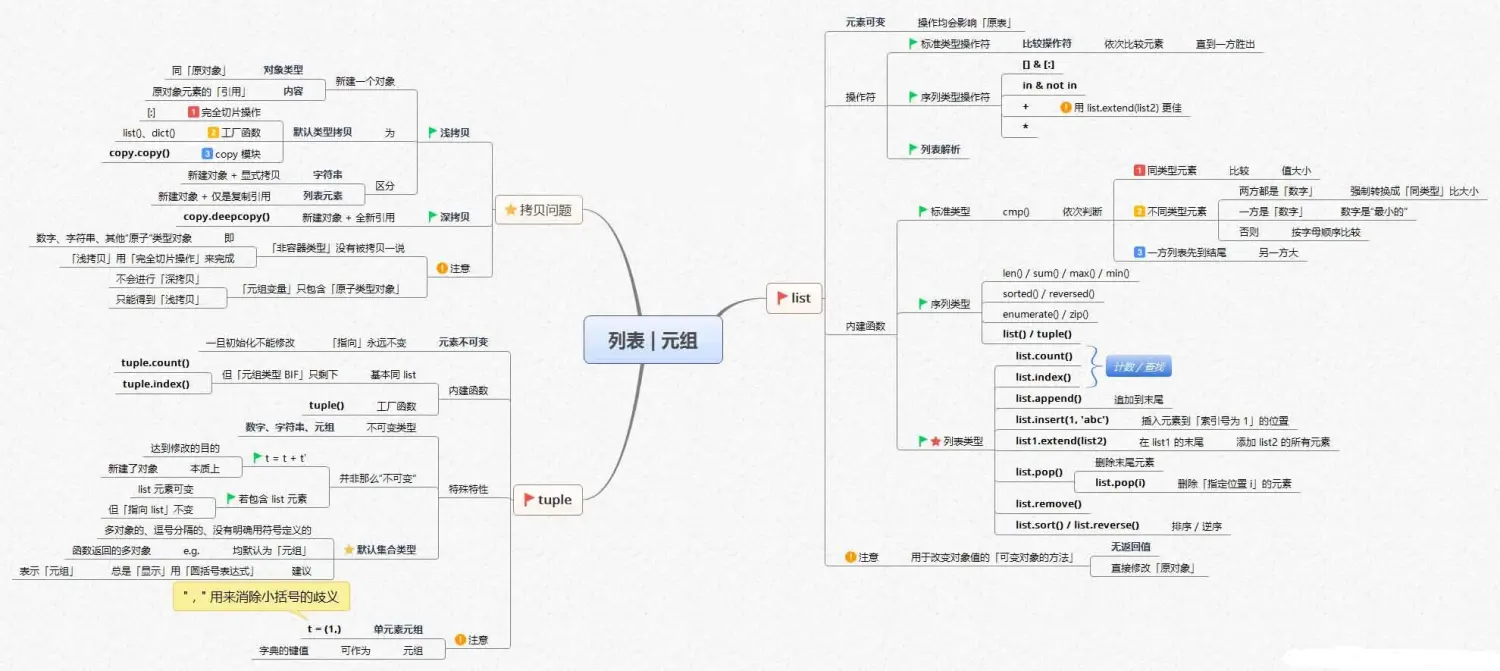
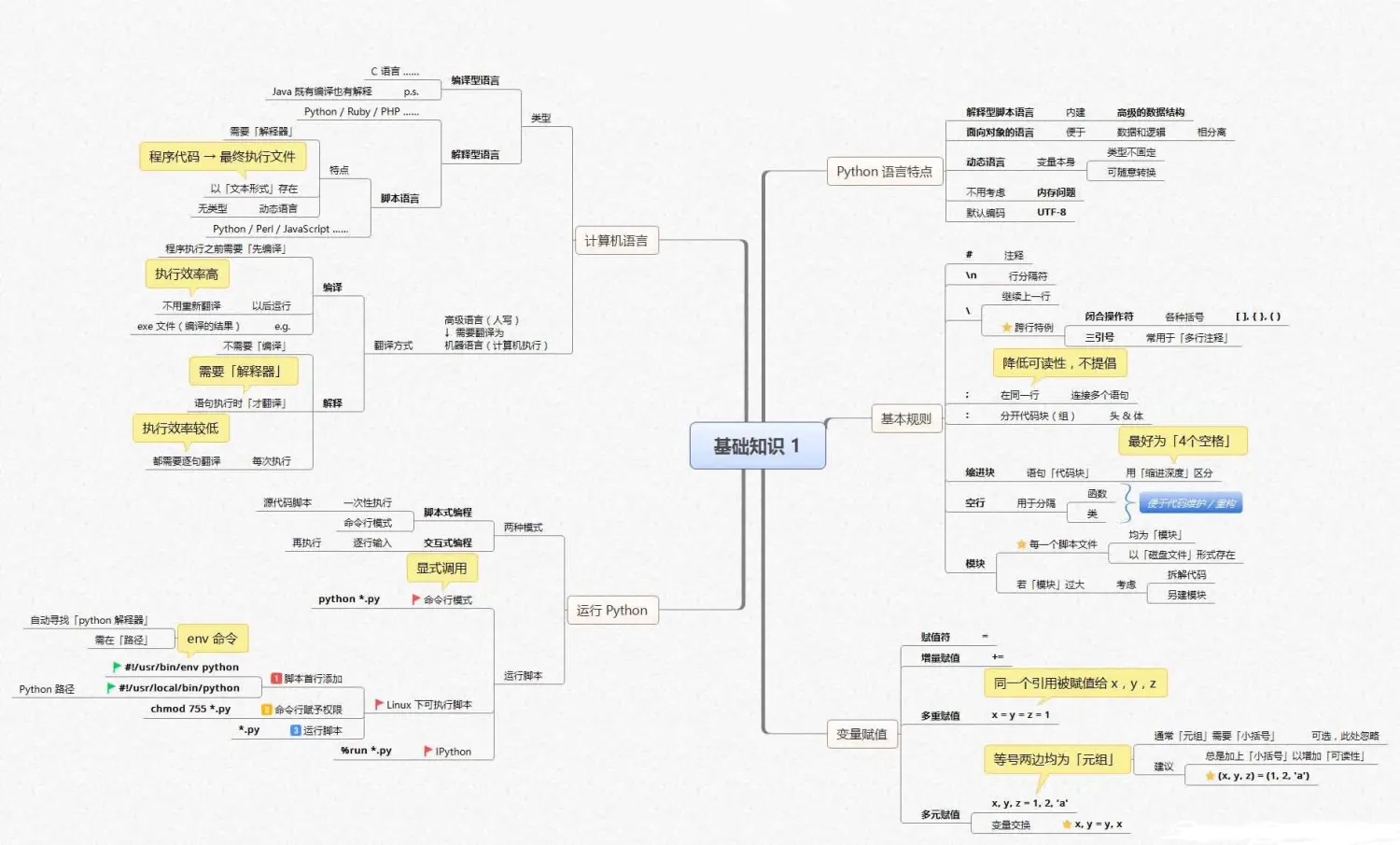
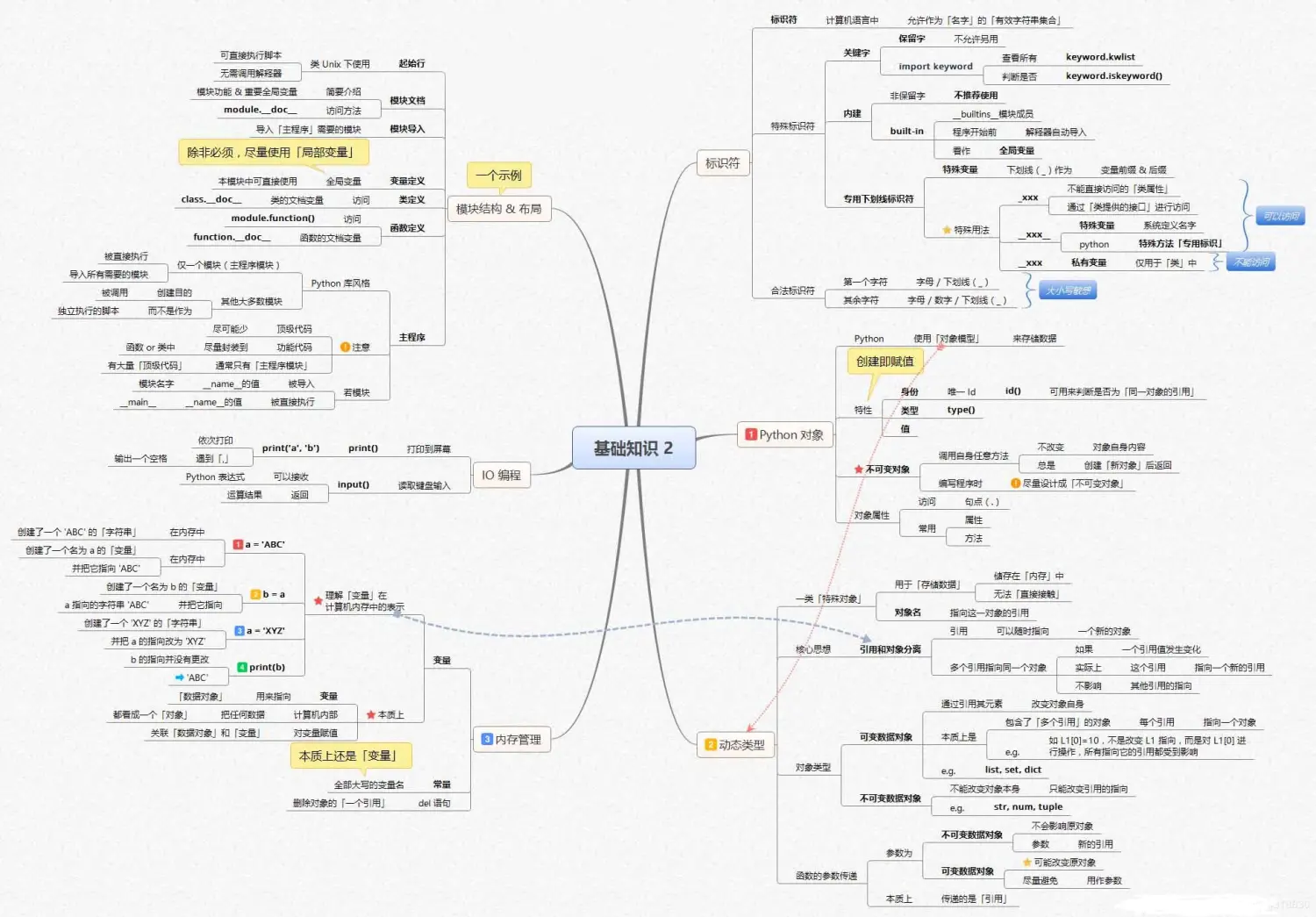
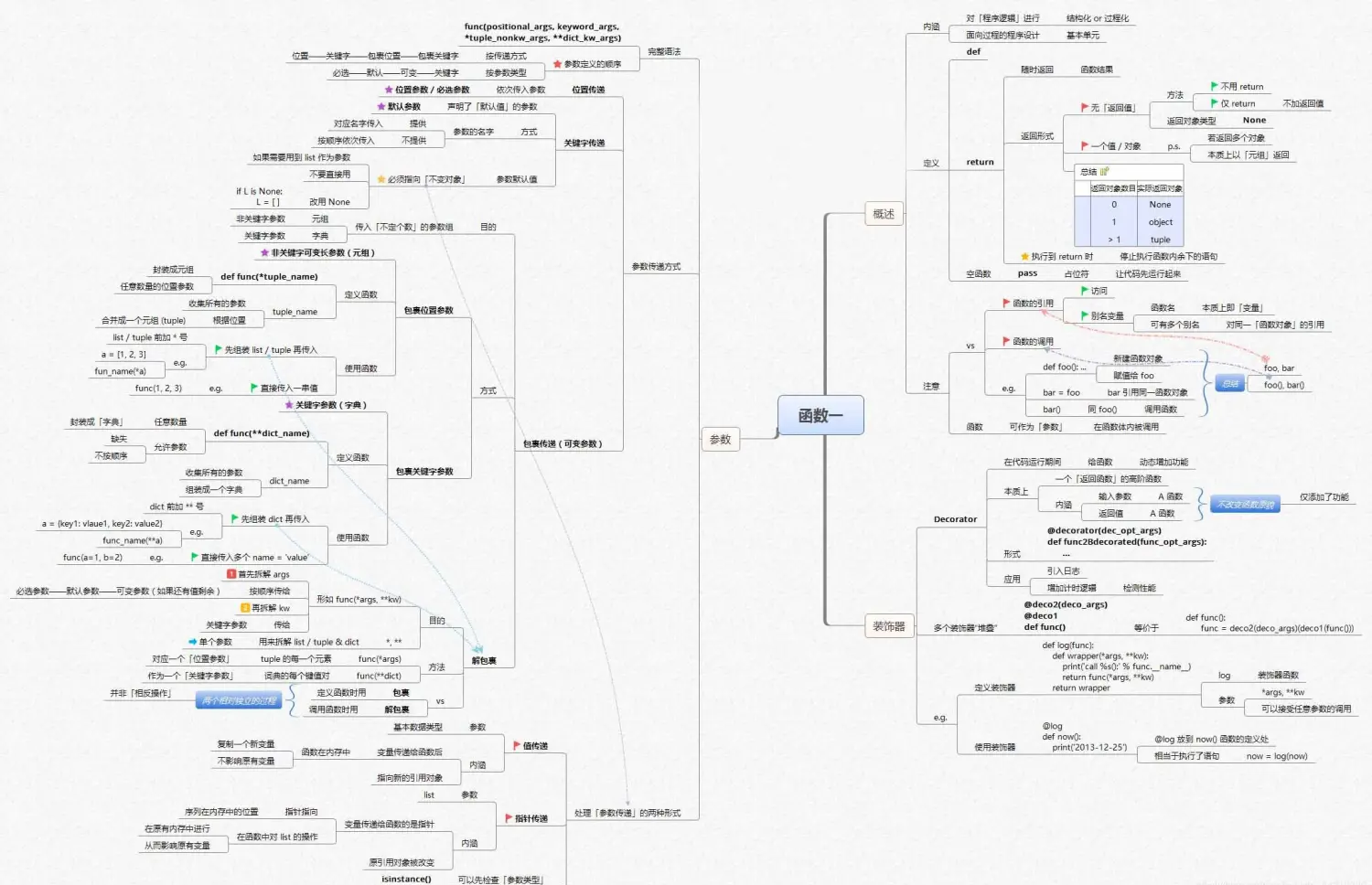
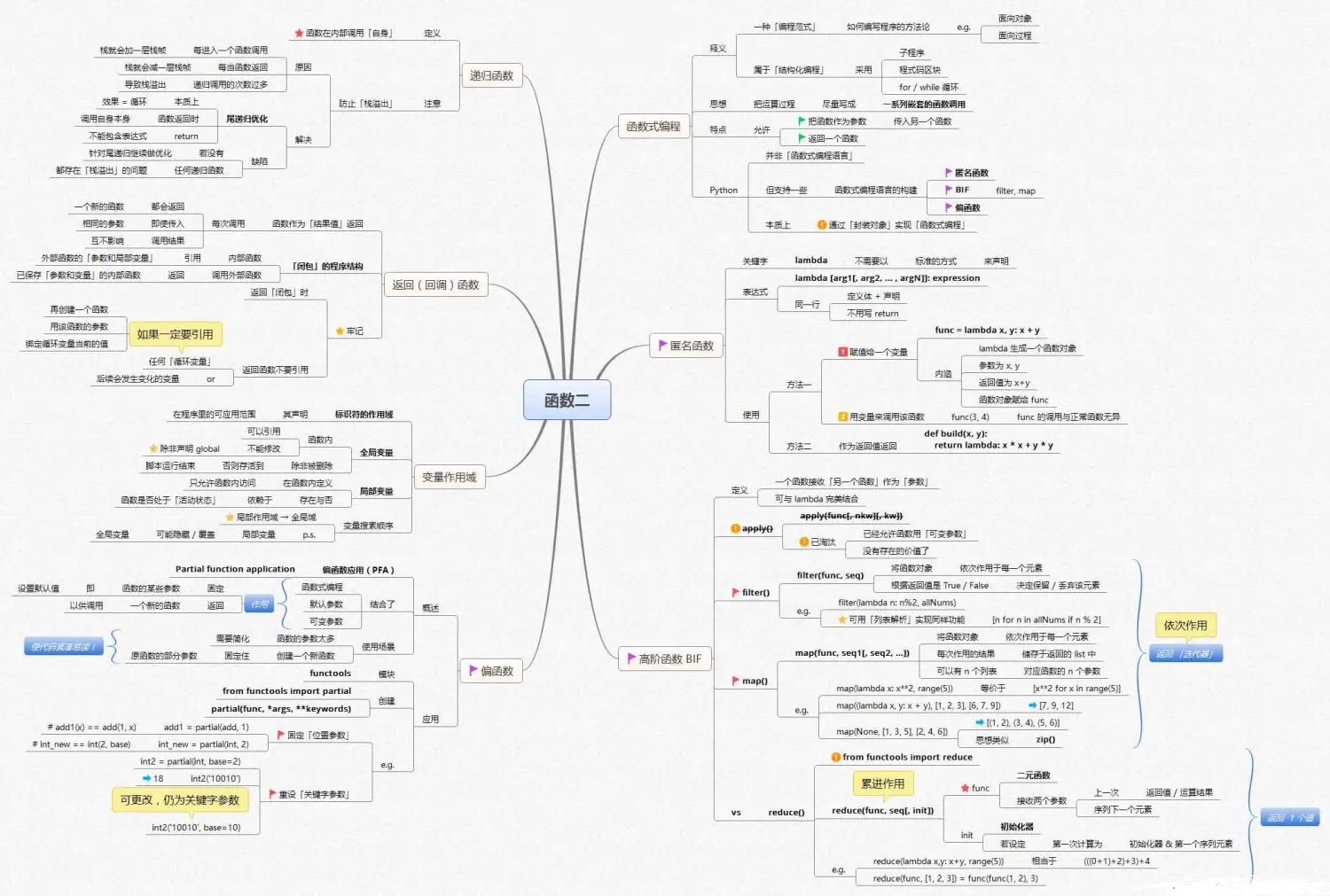
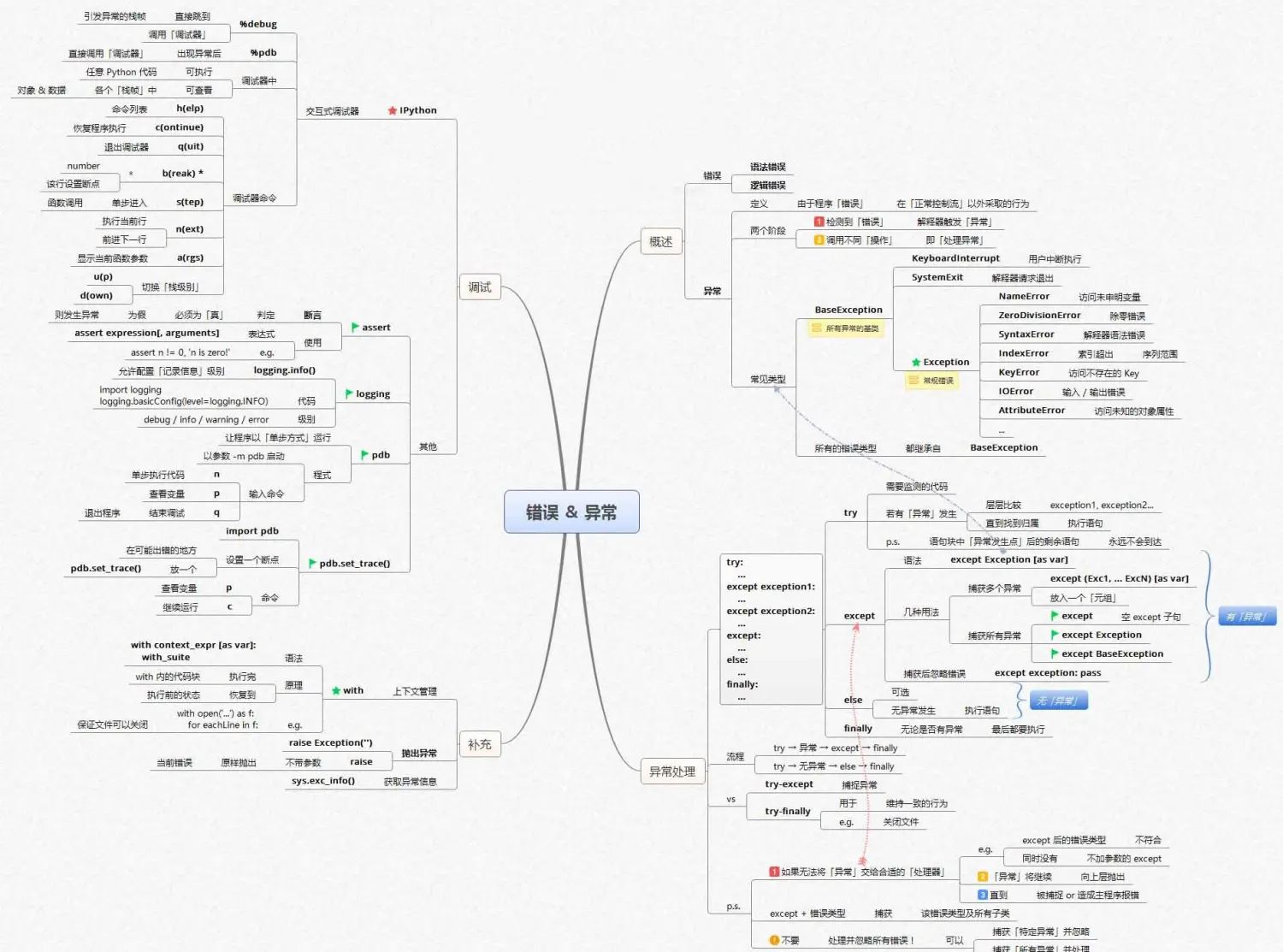
数据清洗及预分析
很多时候我们拿到的数据是不干净的,数据的重复、缺失、异常值等等。这时候就需要进行数据的清洗,把这些影响分析的数据处理好,才能获得更加精确地分析结果。比如空气质量的数据,其中有很多天的数据由于设备的原因是没有监测到的,有一些数据是记录重复的,还有一些数据是设备故障时监测无效的。比如用户行为数据,有很多无效的操作对分析没有意义,就需要进行删除。
·选择:数据访问(标签、特定值、布尔索引等)
·缺失值处理:对缺失数据行进行删除或填充
·重复值处理:重复值的判断与删除
·空格和异常值处理:清楚不必要的空格和极端、异常数据
·相关操作:描述性统计、Apply、图形绘制等
从数据处理开始,就需要介入编程知识了,但不必把Python的教程完全啃一遍,只需要掌握数据分析必备的那部分即可。
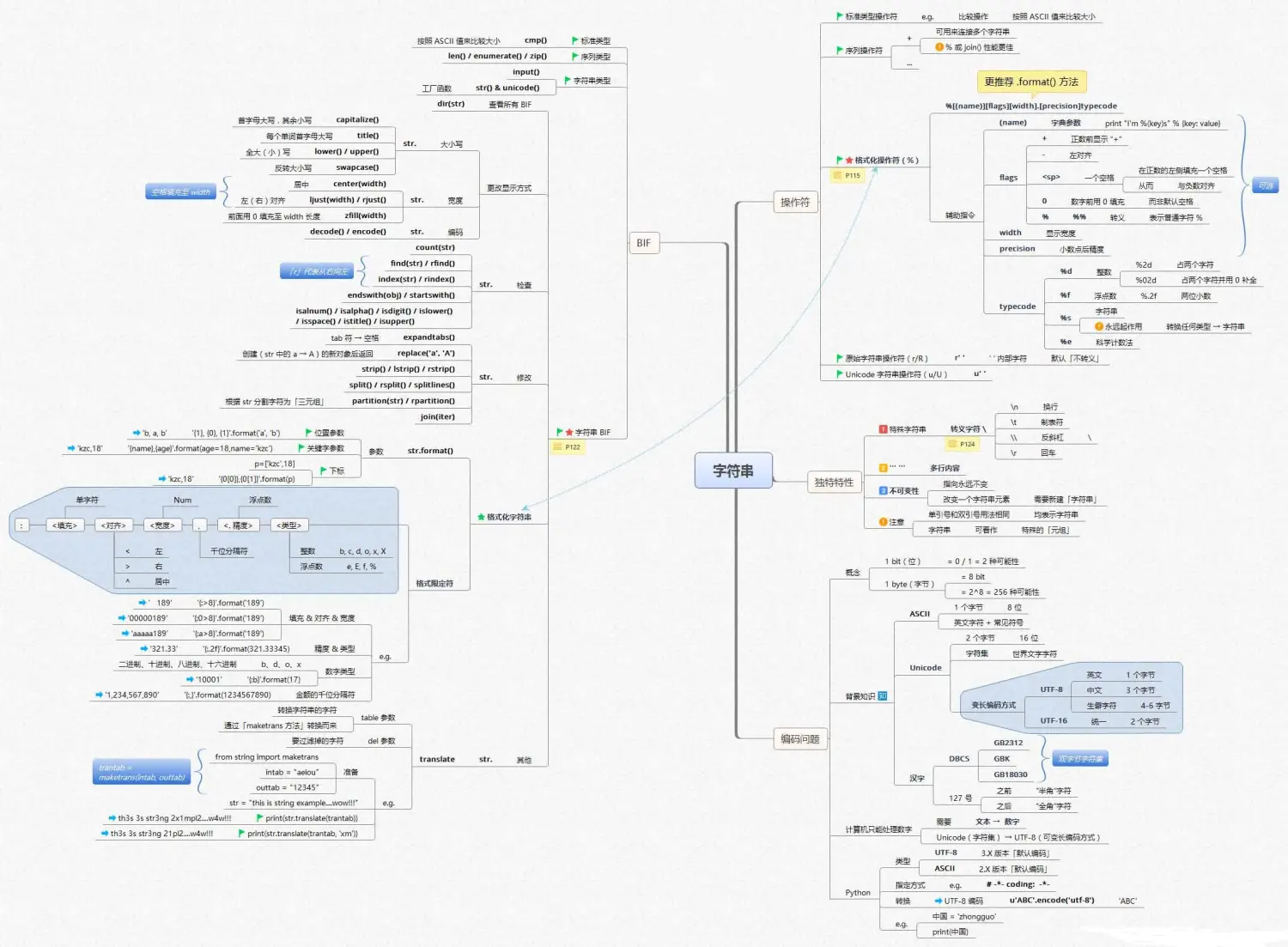
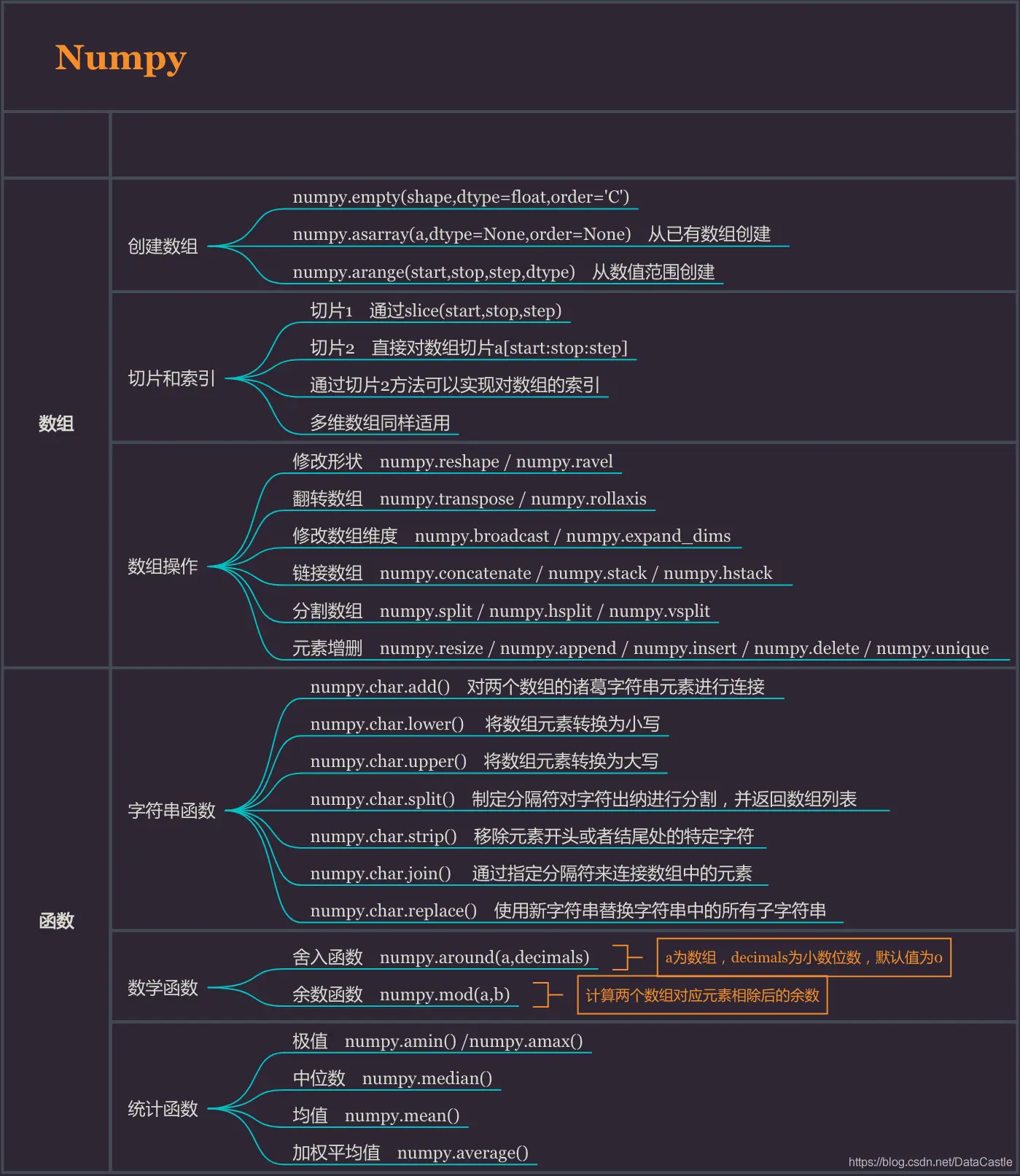
·基本的数据类型:比如字符串、列表、字典、元组,不同的数据类型如何创建、进行增、删、改等操作,以及其中常用的函数及方法;
·Python函数:学习如何去创建自己的函数,实现更丰富的定制化程序,知道在使用中如何调用;
·控制语句:主要是条件语句和循环语句,利用不同的语句对流程进行控制,这是实现程序的自动化的基础。
Python教程推荐:
Python3-菜鸟教程 https://dwz.cn/2nJnWkrp
Python练手项目合集 https://dwz.cn/cpM0jua5
Python基础知识框架如下:
另外,Python中两个非常重要的库Numpy和Pandas也是需要掌握的,我们的很多数据处理及分析方法就源于其中。如果把Python比作是我们的房子,为我们提供基础的框架,那么Numpy和Pandas就是房子里的家具和电器,为我们入住提供各种功能。当然,即便只是这两个库,官方文档的内容也是非常多的,建议先掌握最常用的一些方法,这样你可以解决大部分的实际问题,若后续遇到问题可以有针对性地去查询文档。
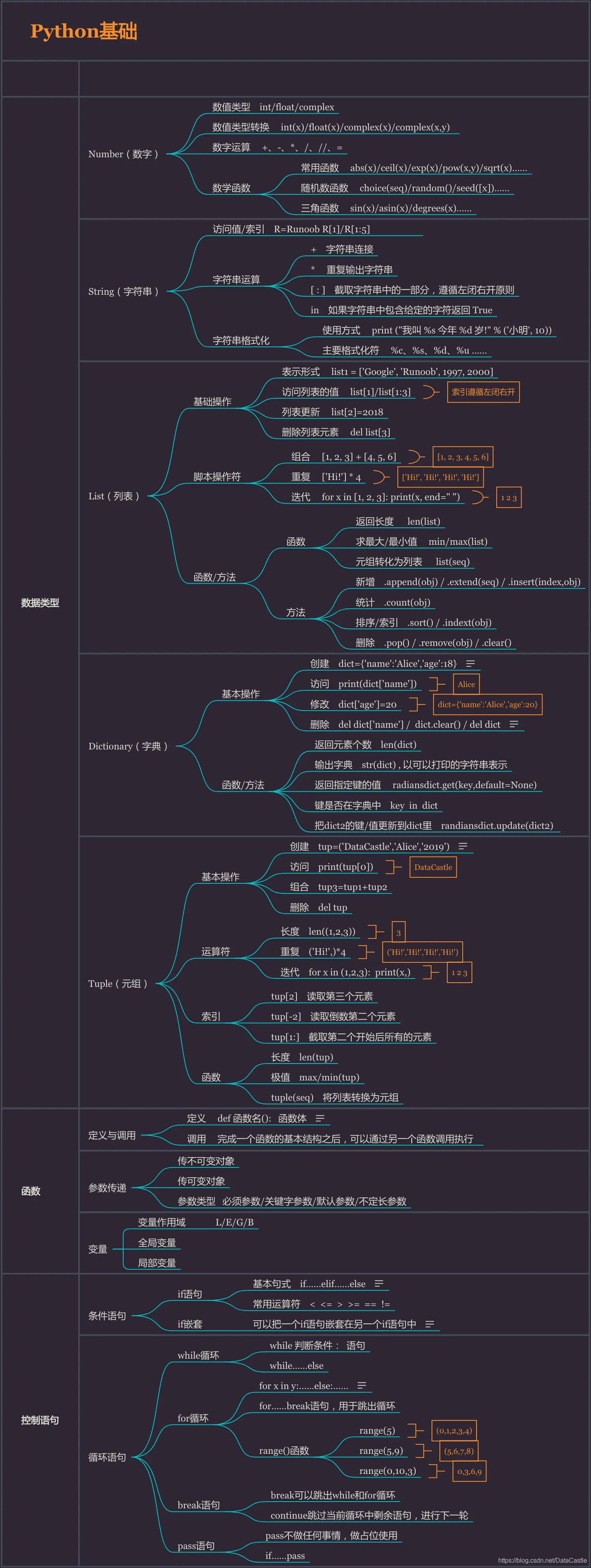
Numpy
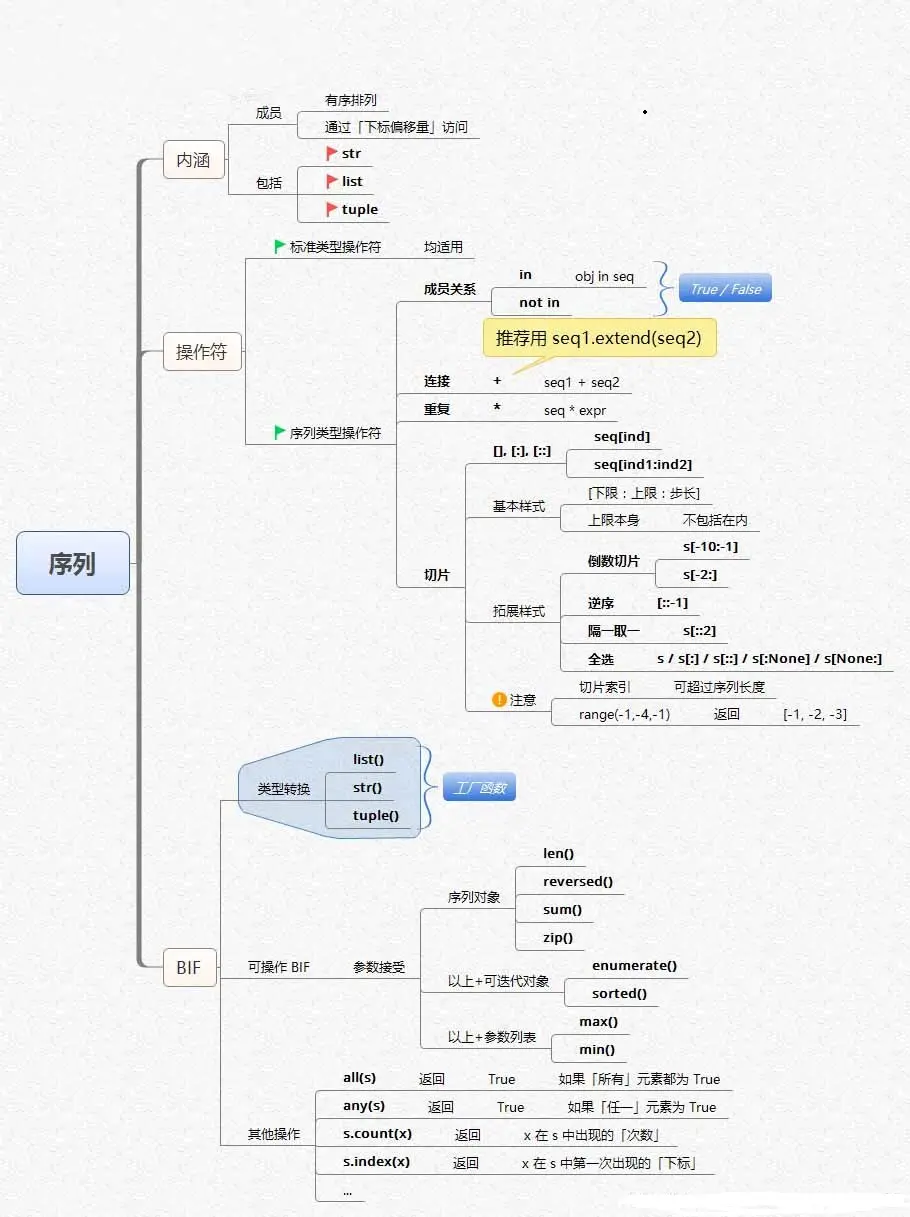
·数组创建:从已有的数组创建、从数值范围创建
·数组切片:通过切片进行选择
·数组操作:元素增删、数组维度修改、数组的分割及连接
·Numpy函数:字符串函数、数学函数、统计函数
推荐Numpy文档:
Nump快速入门 http://h5ip.cn/ypHr
Numpy中文文档 https://www.numpy.org.cn/
Numpy知识框架如下:
Pandas
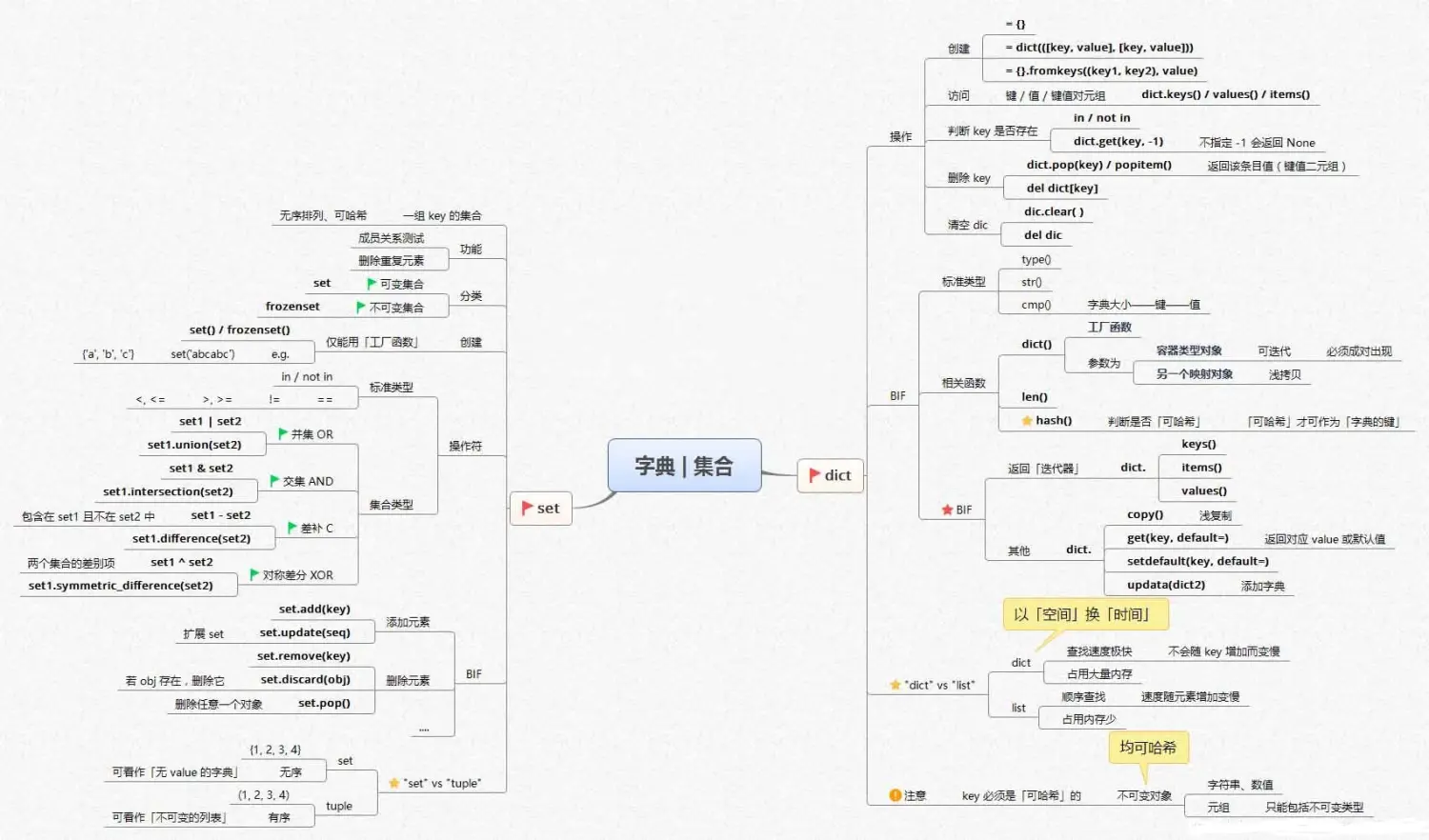
·数据准备:数据读取、创建数据表
·数据查看:查看数据基本信息、查找空值和唯一值
·数据清洗:缺失值处理、重复值处理、字符处理
·数据提取:按标签值进行提取、按位置进行提取
·数据统计:采样、汇总、基本的统计量计算
推荐Pandas文档:
十分钟入门Pandas http://t.cn/EVTGis7
Pandas中文文档 https://www.pypandas.cn/
Pandas知识框架如下:
数据清洗是数据预处理的重要组成部分,也是耗时间最长的一部分,因此根本多篇文章总结脑图便于自己梳理清楚数据清洗的处理步骤,由此知道数据清洗该如何下手。
借鉴文章及数据如下:
专栏1:数据清洗https://zhuanlan.zhihu.com/dataclean :详细介绍了数据清洗的主要方面
专栏2:python3 pandas库https://zhuanlan.zhihu.com/c_129235459:数据清洗主要用pandas库,其中有很多函数众多,该专栏将主要函数介绍的相对清楚
书籍:《利用python进行数据分析》

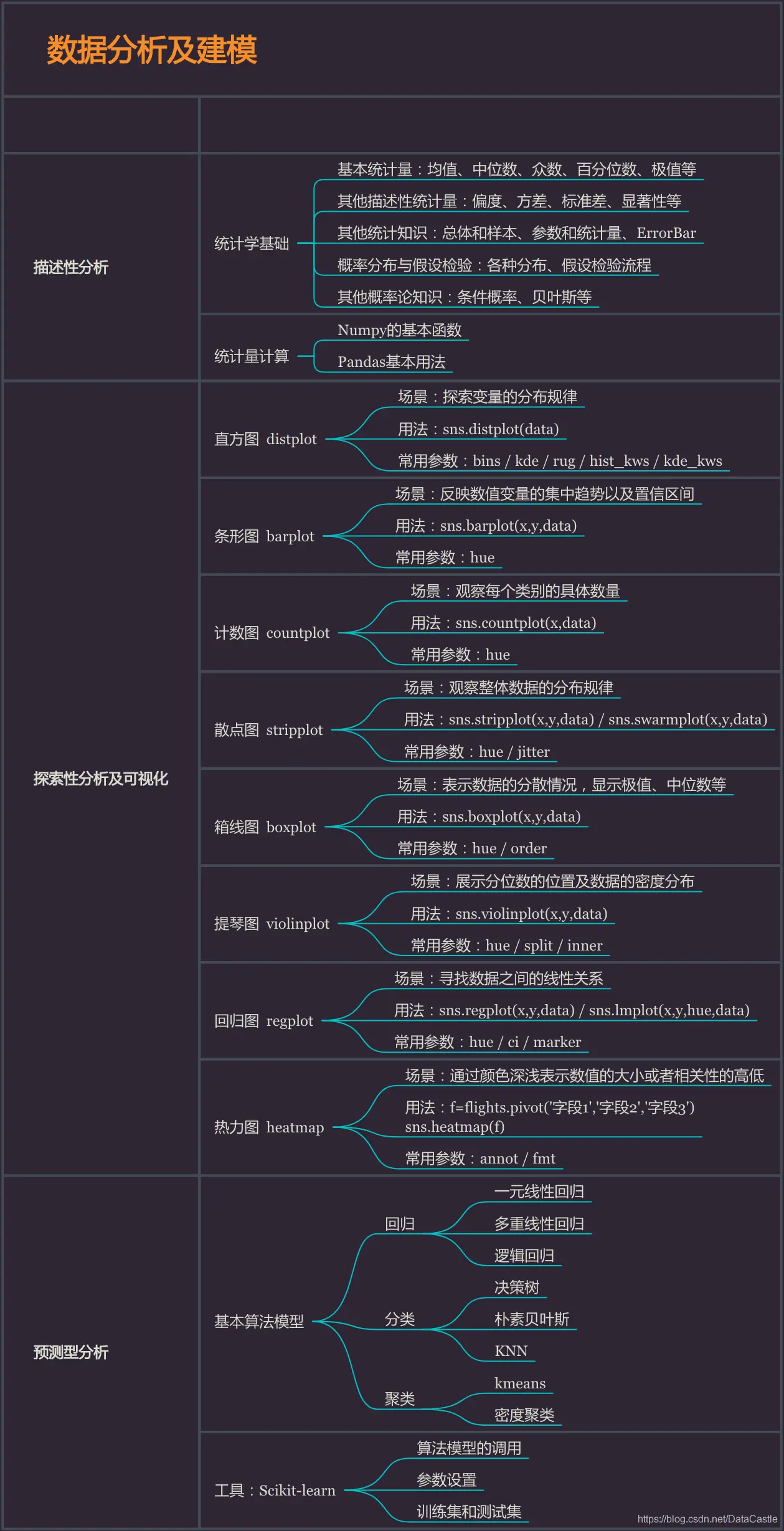
数据分析及建模
如果你有一些了解的话,就知道目前市面上其实有很多 Python 数据分析的书籍,但每一本都很厚,学习阻力非常大。如果没有整体的认识,往往不知道为什么要学习这些操作,这在数据分析中到底起什么样的作用。为了得出普遍意义上的结论(或者从一般的数据分析项目来看),我们通常要进行三种类型的数据分析:描述性分析、探索性分析以及预测性分析。
描述性分析主要是有目的去描述数据,这就要借助统计学的知识,比如基本的统计量、总体样本、各种分布等等。
通过这些信息,我们可以获得对数据的初步感知,也能够得到很多简单观察得不到的结论。
所以其实描述性的分析主要需要两个部分的知识,其一是统计学的基础,其二是实现描述性的工具,用上述 Numpy 和 Pandas 的知识即可实现。
探索性分析通常需要借助可视化的手段,利用图形化的方式,更进一步地去观看数据的分布规律,发现数据里的知识,得到更深入的结论。
所谓“探索”,事实上有很多结论我们是无法提前预知的,图形则弥补了观察数据和简单统计的不足。
Python中的Seaborn和Matplotlib库都提供了强大的可视化功能。
相对于Matplotlib,Seaborn更加简单易于理解,画基本的图形也就是几行代码的事情,更推荐初学使用。
如后续需要定制化图形,可进一步了解Matplotlib。
预测性的数据分析主要用于预测未来的数据,比如根据历史销售数据预测未来某段时间的销售情况,比如通过用户数据预测未来用户的行为……
预测性分析稍难,越深入会涉及更多数据挖掘、机器学习的知识,所以可以只做做基本了解(或者等有需求的时候再学习)。
比如基本的回归、分类算法,以及如何用Python的scikit-learn库去实现,至于机器学习相关的算法选择、模型调优则不必深入(除非你游刃有余)。
推荐数据分析资料:
书籍《深入浅出统计学》《商务与经济统计学》
Matplotlib中文文档 https://www.matplotlib.org.cn
十分钟掌握Seaborn https://dwz.cn/4ePGzwAg
Scikit-learn中文文档 http://sklearn.apachecn.org
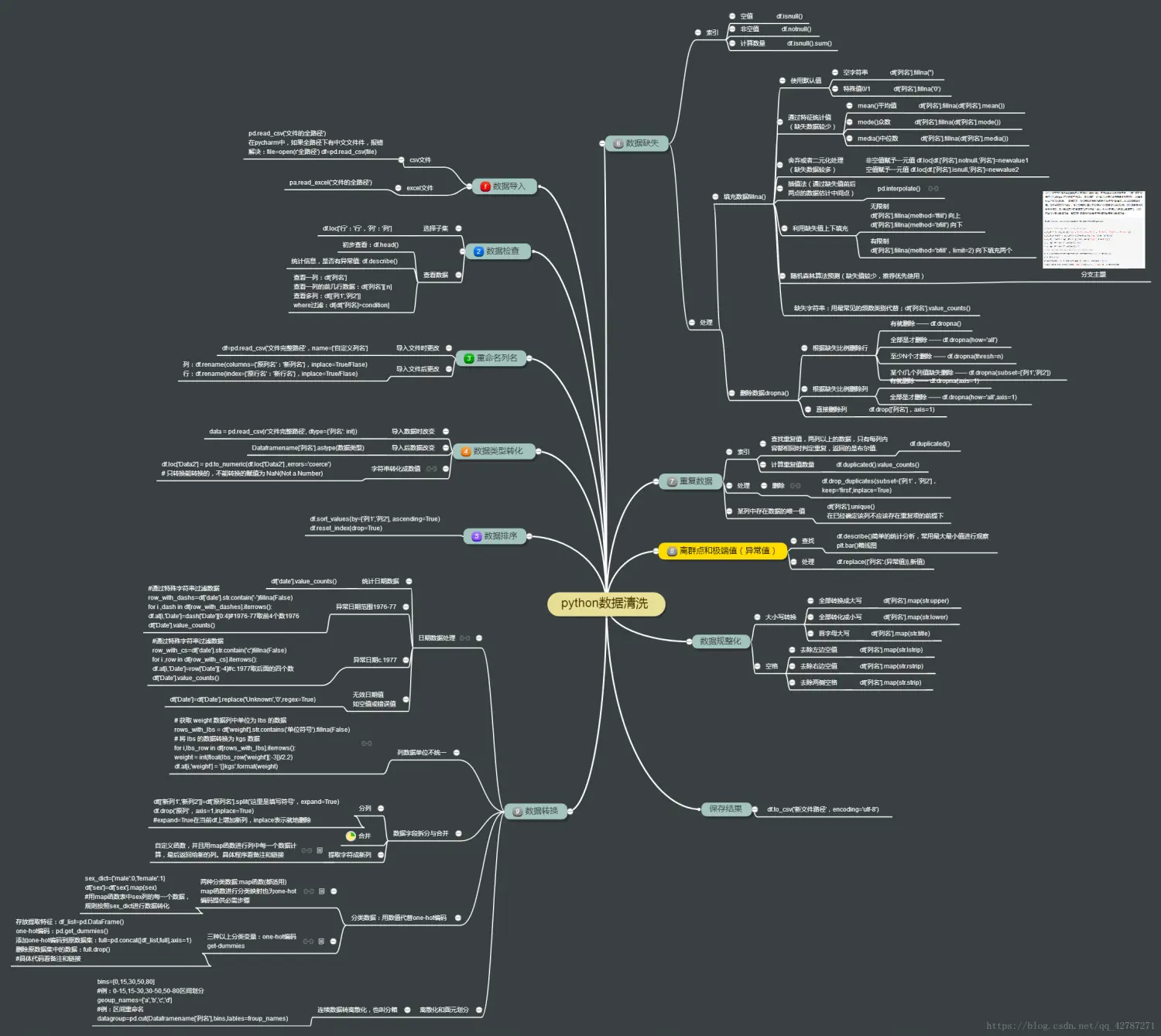
数据分析建模知识框架如下:
撰写数据报告
数据报告是整个数据分析项目的最终呈现,也是所有分析过程的总结,输出结论和策略的部分。所以无论你的心路历程多么精彩,数据报告才是最终决定你分析价值的产物。要写好一个分析报告,首先要明确数据分析任务的目标,是要探索数据里的知识,还有要对产品进行优化,或者预测未来的数据。针对这些目标,那么需要对问题进行拆分,要达到目标,必须要输出哪些有价值的信息。
对于最终的决策,哪些数据、信息是有用的,是否要进一步探索,哪些是无效的,是否直接丢弃。确定好输出的大致内容、在数据分析过程中得到有用的结论之后,接下来应该思考,如何把这些分散的信息整合起来,为了达到最终的说服力,应该以怎样的逻辑进行整合。
这是一个建立框架的过程,同时也反映这这个问题的拆解思路。在搭建好框架之后,就是把已有的结论填充进去,选择合适的表达形式。选择更合适的数据,哪些需要更加直观的图表,哪些结论需要进行详细的解释,并进行最终的美化设计,这样一份完整的数据分析报告也就完成了。
在写分析报告时,有一些一定要注意的地方:
1.一定要有框架,最简单的就是以问题拆分的逻辑来进行搭建,在每个分支进行内容填充,分点说明;
2.数据的选择不要过于片面,要多元化,进行对比分析,否则结论可能有失偏颇。
数据的价值决定了分析项目的上限,尽可能多收集有用的数据,进行多维度的分析;
3.结论一定要有客观的数据论证,或者严密的逻辑推导,否则没有说服力,特别容易陷入自嗨;
4.图表比文字更加直观,而且可读性更高,应该多利用图形化的表达方式;
5.分析报告不只是要说明问题,更重要的是基于问题提出建议、解决方案、预测趋势;
6.多看行业报告,多练习,Business Sense 在后期比技巧更重要。
推荐数据报告相关网站:
艾瑞网-数据报告 http://report.iresearch.cn/
友盟+-数据报告 http://t.cn/EVT6Z6z
世界经济论坛报告 http://t.cn/RVncVVv
普华永道行业报告 http://t.cn/RseRaoE
撰写数据报告的框架如下:
以上就是Python数据分析完整的学习路径,只需要一些业务的常识,像均值、极值、排序、相关性、中位数……这些东西我们信手捏来的东西往往占据数据分析的绝大多数内容,你所学的只不过是实现这些的工具而已。就像一个100行的数据,给任何一个智力正常的人,不用任何工具和编程技术,他也能获得一份基本的结论,而工具则是让我们在效率、可扩展性和实现维度方面得到更好的提升.
链接:https://www.jianshu.com/p/5e3b0e76f653