数字化运营基础技能 – 客户特征的聚类分析实践案例
# 导入库
import pandas as pd # panda库
import numpy as np
import matplotlib.pyplot as plt # 导入matplotlib库
from sklearn.preprocessing import MinMaxScaler # 标准化库
from sklearn.cluster import KMeans # 导入sklearn聚类模块
from sklearn.metrics import silhouette_score # 效果评估模块, 新版本中已经没有 calinski_harabaz_score 方法
import matplotlib.pyplot as plt # 图形库# 读取数据
raw_data = pd.read_csv(‘cluster.txt’) # 导入数据文件
numeric_features = raw_data.iloc[:,1:3] # 数值型特征
# 数据标准化
scaler = MinMaxScaler()
scaled_numeric_features = scaler.fit_transform(numeric_features)
print(scaled_numeric_features[:,:2])# 训练聚类模型
n_clusters = 3 # 设置聚类数量
model_kmeans = KMeans(n_clusters=n_clusters, random_state=0) # 建立聚类模型对象
model_kmeans.fit(scaled_numeric_features) # 训练聚类模型# 模型效果指标评估
# 总样本量,总特征数
n_samples, n_features = raw_data.iloc[:,1:].shape
print('samples: %d \t features: %d' % (n_samples, n_features))
# 非监督式评估方法
silhouette_s = silhouette_score(scaled_numeric_features, model_kmeans.labels_, metric='euclidean') # 平均轮廓系数
# calinski_harabaz_s = calinski_harabaz_score(scaled_numeric_features, model_kmeans.labels_) # 老版本有,新版本没有该方法了
# unsupervised_data = {'silh':[silhouette_s],'c&h':[calinski_harabaz_s]} # 老版本方法
unsupervised_data = {'silh':[silhouette_s]} # 新版本方法
unsupervised_score = pd.DataFrame.from_dict(unsupervised_data)
print('\n','unsupervised score:','\n','-'*60)
print(unsupervised_score)# 合并数据和特征
# 获得每个样本的聚类类别
kmeans_labels = pd.DataFrame(model_kmeans.labels_,columns=['labels'])
# 组合原始数据与标签
kmeans_data = pd.concat((raw_data,kmeans_labels),axis=1)
print(kmeans_data.head())# 计算不同聚类类别的样本量和占比
label_count = kmeans_data.groupby(['labels'])['SEX'].count() # 计算频数
label_count_rate = label_count/ kmeans_data.shape[0] # 计算占比
kmeans_record_count = pd.concat((label_count,label_count_rate),axis=1)
kmeans_record_count.columns=['record_count','record_rate']
print(kmeans_record_count.head())# 计算不同聚类类别数值型特征 'AVG_ORDERS',
kmeans_numeric_features = kmeans_data.groupby(['labels'])['AVG_MONEY'].mean()
kmeans_avg_orders = kmeans_data.groupby(['labels'])['AVG_ORDERS'].mean()
print(kmeans_numeric_features)
print(kmeans_numeric_features.head())# 计算不同聚类类别分类型特征
active_list = []
sex_gb_list = []
unique_labels = np.unique(model_kmeans.labels_)
for each_label in unique_labels:
each_data = kmeans_data[kmeans_data['labels']==each_label]
active_list.append(each_data.groupby(['IS_ACTIVE'])['USER_ID'].count()/each_data.shape[0])
sex_gb_list.append(each_data.groupby(['SEX'])['USER_ID'].count()/each_data.shape[0])
kmeans_active_pd = pd.DataFrame(active_list)
kmeans_sex_gb_pd = pd.DataFrame(sex_gb_list)
kmeans_string_features = pd.concat((kmeans_active_pd,kmeans_sex_gb_pd),axis=1)
kmeans_string_features.index = unique_labels
print(kmeans_string_features.head())features_all2 = pd.concat((kmeans_record_count,kmeans_numeric_features,kmeans_avg_orders,kmeans_string_features),axis=1)
print(features_all2.head())# 合并所有类别的分析结果
features_all = pd.concat((kmeans_record_count,kmeans_numeric_features,kmeans_avg_orders,kmeans_string_features),axis=1)
print(features_all.head())# 可视化图形展示
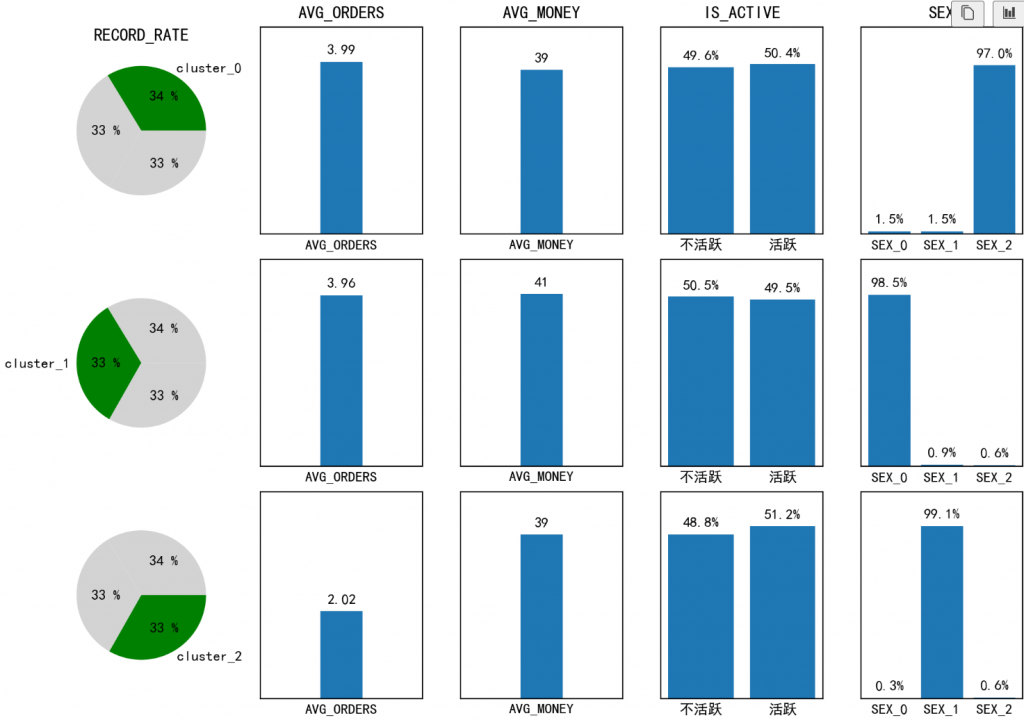
# part 1 全局配置
fig = plt.figure(figsize=(10, 7))
titles = ['RECORD_RATE','AVG_ORDERS','AVG_MONEY','IS_ACTIVE','SEX'] # 共用标题
line_index,col_index = 3,5 # 定义网格数
ax_ids = np.arange(1,16).reshape(line_index,col_index) # 生成子网格索引值
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
# part 2 画出三个类别的占比
pie_fracs = features_all['record_rate'].tolist()
for ind in range(len(pie_fracs)):
ax = fig.add_subplot(line_index, col_index, ax_ids[:,0][ind])
init_labels = ['','',''] # 初始化空label标签
init_labels[ind] = 'cluster_{0}'.format(ind) # 设置标签
init_colors = ['lightgray', 'lightgray', 'lightgray']
init_colors[ind] = 'g' # 设置目标面积区别颜色
ax.pie(x=pie_fracs, autopct='%3.0f %%',labels=init_labels,colors=init_colors)
ax.set_aspect('equal') # 设置饼图为圆形
if ind == 0:
ax.set_title(titles[0])
# part 3 画出AVG_ORDERS均值
avg_orders_label = 'AVG_ORDERS'
avg_orders_fraces = features_all[avg_orders_label]
for ind, frace in enumerate(avg_orders_fraces):
ax = fig.add_subplot(line_index, col_index, ax_ids[:,1][ind])
ax.bar(x=unique_labels,height=[0,avg_orders_fraces[ind],0])# 画出柱形图
ax.set_ylim((0, max(avg_orders_fraces)*1.2))
ax.set_xticks([])
ax.set_yticks([])
if ind == 0:# 设置总标题
ax.set_title(titles[1])
# 设置每个柱形图的数值标签和x轴label
ax.text(unique_labels[1],frace+0.4,s='{:.2f}'.format(frace),ha='center',va='top')
ax.text(unique_labels[1],-0.4,s=avg_orders_label,ha='center',va='bottom')
# part 4 画出AVG_MONEY均值
avg_money_label = 'AVG_MONEY'
avg_money_fraces = features_all[avg_money_label]
for ind, frace in enumerate(avg_money_fraces):
ax = fig.add_subplot(line_index, col_index, ax_ids[:,2][ind])
ax.bar(x=unique_labels,height=[0,avg_money_fraces[ind],0])# 画出柱形图
ax.set_ylim((0, max(avg_money_fraces)*1.2))
ax.set_xticks([])
ax.set_yticks([])
if ind == 0:# 设置总标题
ax.set_title(titles[2])
# 设置每个柱形图的数值标签和x轴label
ax.text(unique_labels[1],frace+4,s='{:.0f}'.format(frace),ha='center',va='top')
ax.text(unique_labels[1],-4,s=avg_money_label,ha='center',va='bottom')
# part 5 画出是否活跃
axtivity_labels = ['不活跃','活跃']
x_ticket = [i for i in range(len(axtivity_labels))]
activity_data = features_all[axtivity_labels]
ylim_max = np.max(np.max(activity_data))
for ind,each_data in enumerate(activity_data.values):
ax = fig.add_subplot(line_index, col_index, ax_ids[:,3][ind])
ax.bar(x=x_ticket,height=each_data) # 画出柱形图
ax.set_ylim((0, ylim_max*1.2))
ax.set_xticks([])
ax.set_yticks([])
if ind == 0:# 设置总标题
ax.set_title(titles[3])
# 设置每个柱形图的数值标签和x轴label
activity_values = ['{:.1%}'.format(i) for i in each_data]
for i in range(len(x_ticket)):
ax.text(x_ticket[i],each_data[i]+0.05,s=activity_values[i],ha='center',va='top')
ax.text(x_ticket[i],-0.05,s=axtivity_labels[i],ha='center',va='bottom')
# part 6 画出性别分布
sex_data = features_all.iloc[:,-3:]
x_ticket = [i for i in range(len(sex_data))]
sex_labels = ['SEX_{}'.format(i) for i in range(3)]
ylim_max = np.max(np.max(sex_data))
for ind,each_data in enumerate(sex_data.values):
ax = fig.add_subplot(line_index, col_index, ax_ids[:,4][ind])
ax.bar(x=x_ticket,height=each_data) # 画柱形图
ax.set_ylim((0, ylim_max*1.2))
ax.set_xticks([])
ax.set_yticks([])
if ind == 0: # 设置标题
ax.set_title(titles[4])
# 设置每个柱形图的数值标签和x轴label
sex_values = ['{:.1%}'.format(i) for i in each_data]
for i in range(len(x_ticket)):
ax.text(x_ticket[i],each_data[i]+0.1,s=sex_values[i],ha='center',va='top')
ax.text(x_ticket[i],-0.1,s=sex_labels[i],ha='center',va='bottom')
plt.tight_layout(pad=0.8) #设置默认的间距