2023.11.12 阿里云的史诗级故障,故障原因曝光
2023年11月12日,双十一刚过,一大片阿里的产品都挂了,来了一波“史诗级”大翻车。
阿里云断网并不少见,但这种全面崩溃在历史上还是第一次,全国所有数据中心全军覆没,阿里所有产品全军覆没!

阿里云官方的通知是:
“2023年11月12日17:44起,阿里云产品控制台访问及API调用出现异常……20:12 北京、杭州等地域消息队列MQ已完成重启,其余地域逐步恢复中。”
在出问题的这接近两个多小时时间里,淘宝买不了东西、饿了么点不了外卖、骑手进不了系统、停车场不抬杆、超市无法结账,甚至支付宝也登不上去了。一位网友笑称:“别的都需要尽快恢复,只有钉钉希望恢复慢点。”阿里自己的系统都自顾不暇了,更别说阿里云客户的中小互联网公司了,一夜之间,全国互联网行业再次哀鸿遍野。
公有云断网,并不是新鲜事物,其他更大的云厂也一样断网。相信不久,阿里云就会给用户赔偿和解释,作为国内第一大云厂,阿里云自然会承担相应责任。但是,这次断网范围之大,却前所未有。
与以往非常不同的是,大多云计算的用户,包括阿里云的前员工,并不认为本次阿里云断网是单纯的技术问题,而是……
影响范围
1、OSS、OTS、SLS、MNS 等产品的部分服务受到影响,大部分产品如 ECS、RDS、网络等运行不受影响。
2、云产品控制台、管控 API 等功能受到影响。
时间
2023 年 11 月 12 日 17:39~19.20,故障时间为 1 小时 41 分。
问题概况
2023 年 11 月 12 日 17:39 起,阿里云云产品控制台访问及管控 API 调用出现异常、部分云产品服务访问异常,工程师排查故障原因与访问密钥服务 (AK) 异常有关。工程师修订白名单版本后,采取分批重启 AK 服务的措施,于 18:35 开始陆续恢复,19:20 绝大部分 Region 产品控制台和管控 API 恢复。
处理过程
17:39:阿里云云产品控制台访问及管控 API 调用出现异常。
17:50:工程师确认故障是 AK 服务异常导致,影响云产品控制台、管控 API 调用异常,以及依赖 AK 服务的云产品服务运行异常。
18:01:工程师定位到根因。
18:07:开始执行恢复措施,包括修订白名单版本、重启 AK 服务。
18:35:杭州等 Region 开始恢复正常。
19:20:绝大部分 Region 的云产品控制台和管控 API 调用恢复正常。
原因
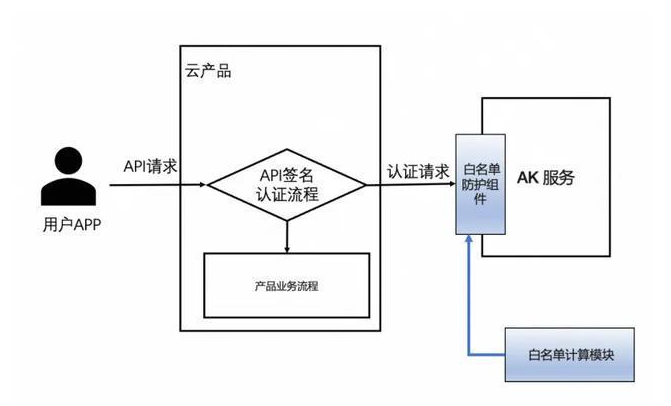
访问密钥服务 (AK)在读取白名单数据时出现读取异常,因处理读取异常的代码存在逻辑缺陷,生成了一份不完整白名单,导致不在此白名单中的有效请求失败,影响云产品控制台及管控 API 服务出现异常,同时部分依赖 AK 服务的产品因不完整的白名单出现部分服务运行异常。
改进措施
1、增加 AK 服务白名单生成结果的校验及告警拦截能力。
2、增加 AK 服务白名单更新的灰度验证逻辑,提前发现异常。
3、增加 AK 服务白名单的快速恢复能力。
4、加强云产品侧的联动恢复能力。
网上记录对故障的反思与总结
对于阿里云这次史诗级故障的发生,我们不得不反思云计算发展中所面临的挑战和问题。尽管云计算的发展给我们带来了巨大的便利和效益,但也存在着安全、可靠性等方面的隐患。
首先,在技术层面上,我们需要更加注重代码的质量和安全性。即使是在白名单生成这个看似简单的环节,也需要精益求精,避免出现逻辑缺陷导致的故障。只有不断完善代码质量,才能保证云计算服务的稳定性和可靠性。
其次,我们需要在故障发生后,尽快采取有效的措施来恢复服务。这次阿里云的工程师们积极应对,通过修订白名单版本等措施,迅速恢复了大部分地区的云产品控制台和管控API服务。这种敏捷的反应能力,对于确保用户体验至关重要。
最后,我们也要加强对人员配备的管理。在互联网公司中,往往会出现技术能力不足或岗位不匹配的情况。为了防止故障的发生,我们需要注重技术团队的培养和管理,确保人员具备足够的专业能力和责任心。
总之,阿里云这次的故障为我们敲响了警钟,提醒我们在云计算发展的道路上,不能忽视技术质量、反应能力和人员管理等方面的重要性。只有不断优化和改进,才能为用户提供更加稳定可靠的云服务。
网上根因猜测
症状分析
首先看到影响面是全球

影响的服务是 API 调用,以及依赖 API 调用的控制台。
像阿里云这样做了单元化的云架构,能引发全球故障的组件并不多。一个是网络,一个是访问系统。
提到了底层服务组件,那基本就是访问系统了。因为如果是网络的话,一般会直接说网络问题。阿里云的访问控制系统叫 RAM (Resource Access Management)
RAM 里的用户和用户组都是全局资源,从 API 的 CreateUser 能看到
相对的其他绝大多数服务的资源都不是全局的,比如 ECS,创建时要指定 Region 地域和 Zone 可用区
变更引起

变更有三种类型,一种是应用代码变更,一种是配置变更,一种是数据库变更。我想可以先排除数据库变更,因为如果是数据库变更的话,故障无法那么快恢复(1 小时的故障不算短,但如果是数据库变更导致的问题,恢复时间会更长,因为要处理脏数据)。

代码变更和配置变更都有可能。猜测代码变更的原因是从恢复的方式看,是以逐步重启组件完成的,那么可能是新的代码版本发出去后,出现了问题,然后又陆续回滚。
不过我更倾向于是配置变更,原因是:
- 一般应用代码的变更,会更严格遵循灰度发布,像 RAM 这种核心服务,新版本往往会按天按地域分批发布,从周一开始一直发布到周四,不太会造成全球级别的故障。虽然 RAM 资源是全局的,但是它服务的接入点是分地域的,所以如果是应用代码 bug 的话,不会一下子全挂。
- RAM 这样的系统会使用不少的配置来控制策略,而配置的发布通常不会有像代码变更那样长时间的灰度过程(因为配置本身就是为了针对能更灵活地改变软件行为而设计的)。有时一个全局配置推送出去后,经过一些简单的检查之后,很快就会同步到各个分区。所以坏的配置更容易造成全球故障。
- 组件重启的原因,也可能是因为配置问题导致内存状态被污染了,所以最快恢复的方式是重启。
非变更引起

但故障发生的时间点在周日下午 17:44,正常是不会在周五以及休息日做变更的。所以也有可能是非变更引起的。可能就是跑 RAM 一个组件的硬件突然坏了,容灾失灵,导致容量不够,结果引起了雪崩,类似下图这样。
工程师恢复服务也需要一定的时间,因为先要做限流,不然新服务刚拉起来,立刻会被无数堆积的请求压垮,又崩了(thundering herd)。所以需要步步为营(bootstrap),慢慢起服务。
差不多就这些吧,重大的事故,往往都是几个小概率事件同时发生的结果。等阿里云官方的复盘报告出来后,再去观摩学习一下,引以为戒。另外也没有必要因为阿里云的这次事故而恐慌,跑到其他云或者下云。
阿里云崩溃,或许并非完全是技术层面的问题。运维的疏漏可能是一个方面,但更需要关注的是企业选择云服务的战略决策。
数字化转型的步伐或许需要更为谨慎,不仅仅是技术的推动,更要考虑基础设施的可靠性。那些曾经对于云服务寄予厚望的企业,此刻是否会对数字化的方向重新思考?
企业中的研发人员也是受害者之一。年终奖成了想象中的奢望,而这不仅仅关系到他们的收入,更是对于付出努力的一种认可。
数字化的时代,研发人员是否需要重新审视自己的职业选择,以及对于企业技术架构的贡献是否能够得到
应有的回报?
技术脆弱性与数字化策略:阿里云崩溃揭示了数字化时代企业面临的技术脆弱性。
企业在数字化策略中是否过于依赖单一云服务提供商,以及是否充分考虑了技术风险?或许,我们需要重新审视多云战略和技术架构的设计。
责任归属与运维管理:企业在面对技术故障时,责任的归属成为关键。
是运维的失误,还是云服务提供商的问题?这牵涉到合同条款、服务水平协议等多个方面。企业在选择云服务时是否足够谨慎,对于合同的审查和责任条款的明晰是否得当?
数字时代的企业经营风险:数字时代带来了前所未有的便利,但也伴随着巨大的经营风险。
企业需要更全面地考虑技术、安全、合规等多方面的挑战。这场云服务的崩溃或许是一个警示,企业需要在数字化转型中保持警觉,防患于未然。
我们不能简单归咎于技术问题,而是需要深入思考云服务在企业运作中的角色。或许是时候重新审视数字化转型的步伐,稳扎稳打,不仅要注重技术创新,更要关注基础设施的可靠性。
通过这次阿里云崩溃,我们看到了数字化时代的脆弱性,企业需要在数字化的道路上更加谨慎前行,不被技术的风险所蒙蔽。同时,也需要在技术和管理的平衡上找到最佳点,避免将所有赌注押在技术的未来上。
数字时代的阿里云崩溃,让无数企业和研发人员陷入困境。在技术风险和年终奖的双重夹击下,我们需要深刻反思数字化时代的企业经营策略,以及云服务的可靠性问题。
未来,如何平衡技术创新和基础设施的稳定性,将是企业发展的关键。
数字风暴过后,企业和研发人员需要重新定义“稳定”与“创新”的平衡,因为在数字时代,没有哪一项能够缺一不可。
或许,正是在这样的风暴中,我们才能看到更远的未来。在纷繁的数字浪潮中,稳健前行,方能迎来更加辉煌的曙光。