故障处理最佳实践 – 滴滴是如何高效处理线上故障的?
故障处理是每个系统都要面对的现实问题,但随着系统越来越复杂,故障的发现、定位、处理难度也将随之增大。滴滴现在服务近 4 亿乘客、1700 多万司机、覆盖 400 多个城市,超过 10 个业务线提供服务,业务的高速增长对稳定性工作来说是个极大的挑战。为了了解滴滴在故障处理以及稳定性建设方面的工作,InfoQ 记者采访了滴滴资深运维工程师张云柳。另外,张云柳也将会在 9 月 10 日举行的 CNUTCon 全球运维技术大会 上分享相关话题,欢迎关注。
InfoQ:可否整体谈一谈,为了提高故障处理的效率,滴滴出行重点做了哪几块工作?
张云柳:稳定性建设是一个很大的话题,涉及到多个部门、各个内部平台之间的协作。这里我主要从整体的处理流程、故障生命周期的分阶段投入分别来说明滴滴如何处理故障,提高处理效率。
在公司层面,滴滴以内部竞赛的形式来促进公司整体的稳定性建设工作开展,是公司级的竞赛之一。每个季度将会总结稳定性建设最好和最差的服务,并有相应奖惩。稳定性技术竞赛在公平公正、数据优先、持续迭代等方面逐步完善的同时,也保障了各个团队的高度参与,积极投入。
稳定性建设在滴滴不是某个部门的重点工作,而是围绕着技术竞赛,全体团队都深度参与的事情。也正是得益于竞赛机制的良性循环,故障发生后,各个可能涉及到的团队都会同时高优跟进,使得故障处理效率得以大幅提高。
从技术思路出发,我们把故障处理分为预防、发现、定位、止损、恢复几个大的阶段。其中发现、定位、止损三个阶段是故障现场的重点阶段,故障处理的效率提升也主要是在这三个阶段。
快速发现除了传统的系统指标监控外,公司整体以业务不可用时长定义业务状态,当任一关键业务指标下跌一定比例,则认为当前业务不可用。这里最大的挑战是准确判断业务指标下跌,并且准确性难以保证,基于该背景,“核心业务监控”重点在异常检测上投入,实现智能报警,使得业务不可用能及时、准确的发现。
快速定位方面,我们的目标是定位到可以确定一个止损预案即可。而定位能力可以说是一个无底洞,比如公网问题需要公网监控、内部交换机问题需要内网监控、机器环境问题需要系统级监控等等,只有相应的监控覆盖之后,才能直观的定位问题,因此各个团队都在发力提升监控覆盖面。但随着监控越来越多,业务规模越来越大,如何快速从众多监控、变更中找到故障根因成为当前的一个难点,建设中的“事件监控”应运而生。事件监控的目标是将各维度的监控报警、各系统的变更以事件的形式整合为一个 timeline,从众多的事件中智能筛选故障根因。
快速止损方面,更重要的是平时对预案的建设,以此提升故障阶段的处理效率。在预案建设上,我们主要从时效性、完备性、可执行性三个方面综合来评估某个系统。时效性是指每个预案都应当有保质期,失效前或架构调整时需 review,根据预案的新鲜程度给予评分;完备性考察各关键系统对预案场景的覆盖率,我们从网络、程序、安全几个方面综合梳理了一个比较通用的场景列表以此来规范各个系统需要建设的预案;可执行性指预案不能只呈现在文字上,还需时常通过演练确定能否达到预期目标,根据预案的执行效率和最终效果进行评分。通过上述的评分机制来引导各个关键系统完善其预案,提升故障处理效率。
InfoQ:监控系统发现问题时,你们一般的处理流程是怎么样的?
张云柳:上面提到了“消防群”沟通机制来保证故障有条不紊的处理,但即使如此,由于业务规模及监控专业度的问题,仍然需要 involve 不少的同学一起进行问题排查。为尽可能规避各个人员信息量不对称的问题,我们维护了一个故障处理最佳实践,参考下图:
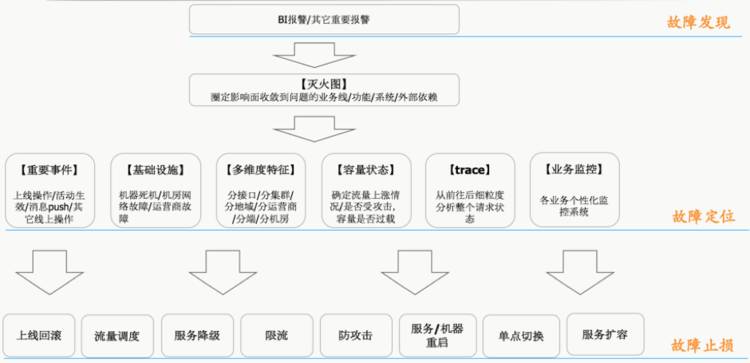
上图勾勒了每次业务故障时,我们的处理、排查思路。通过 BI 业务报警发现业务故障,随即通过“灭火图”快速圈定影响面。在圈定的影响面,通过各个性化的监控来具体定位原因,确定止损方案。更多关于定位环节的细节以及我们在智能定位上的尝试,请一定到现场共同探讨。
InfoQ:监控是避免故障的前提,可否谈谈你们监控系统的架构以及技术栈?
张云柳:监控建设确实是稳定性建设最基础的环节,目前公司内部自研的监控平台作为比较通用的基础监控,提供了采集、数据存储、绘图、报警策略等监控功能,伴随着滴滴的业务发展经历了几次迭代,形成了现在以 OpenFalcon 为基础的监控体系。相对于 OpenFalcon,滴滴的实现有一些自己的改进:根据滴滴用户习惯实现了一个多级索引结构、报警数据获取模式调整等。可以说基于 OpenFalcon 进行了深度定制。感兴趣的朋友可以看看作者的分享“”。
基础监控重点在于基础技术能力的输出,由于各个具体业务方向的特殊性,在展示上需要有贴合业务定制的风格。仅仅展示上的差异如果需要建设完整的监控系统那在各个基础的实现环节还是会有比较大的重复性。因此比较基础的技术能力、规范还是进行的统一的建设:
收敛数据采集方式
目前监控数据的来源主要有日志、运行时主动上报以及 DB 数据。对于日志及 DB 数据采集比较常见,这里主要介绍下运行时主动上报的采集。日志和 DB 采集需要运维同学单独对接具体的业务日志、DB schema,因此借鉴了开源的 statsd 的解决方案,通过业务代码埋点将状态数据上报给监控系统。
数据实时聚合
监控系统采集得来的数据,大多数时候是单个实例的数据。随着业务监控细化,将数据以 idc、来源渠道等等不同的维度聚合展现变成很基本的需求,为此实时计算能力建设成为监控中比较重要的环节。目前主要的实时计算是有实时计算团队基于 Spark Streaming, Flink 实现的。
数据存储能力
监控数据存储受数据量、数据格式及使用方式影响,使用的基础组件各有差别。目前主要使用的有 RRDTool、Druid 和 ES。
异常检测智能化
异常检测是监控数据体现意义最重要的一环。比较传统的方式是根据历史曲线变化人为设定一个上下界进行异常报警,在指标项数量小且业务稳定的情况下,该方式成本小、收效快,是个不错的选择。但是对于滴滴来讲,业务高速发展带来的是监控指标类别变化快、量级变化快。因此我们不得不寻求更加智能的手段进行异常检测,现在主要应用的检测手段有三次指数平滑、上下界训练、斜率判定等手段。
报警事件统一收敛,智能过滤
监控覆盖完善并且异常检测就位后,也带来了一些甜蜜的烦恼——报警轰炸。当一次真实的故障发生后,整条链路的监控数据都会异常,也因此各个系统都会开始产生报警。目前正在将各个系统产生的事件统一收敛到事件库,同时开展基于时间、底层报警优先的基础规则做一些过滤尝试。
监控基础能力建设大概从上述几个方向进行统一能力输出。在智能化方向上的探索目前主要是异常检测及智能定位。异常检测现阶段在监控上应用的比较成熟,当前核心业务指标的报警控制完全是基于预测算法来实现的,误报漏报都比较符合预期。智能定位方向上现阶段刚刚起步,目前正在进行相关的基础建设,比如事件库的统一收敛、事件分类、业务拓扑关系等。
InfoQ:从一开始简单的系统监控到现在独立的监控系统,聊聊你们就监控这件事的迭代思路?
张云柳:监控系统的发展确实经历了几次迭代,但不管如何演变,我觉得还是始终遵循着“快准稳全”来迭代的。
- 从最初使用 Nagios 进行系统监控,到开始自研运维平台及监控系统,主要是贴合业务需求,也建立了滴滴基于 WorldTree 的运维平台体系;
- 后面 Odin 监控的迭代升级分别从数据准确性、监控系统稳定性两方面进行了很多细节打磨;
- 随着业务的不断发展,监控数据不断增涨使得查询速度开始受到影响,因此新版监控系统又在查询速度、数据存储上进行了重大升级;
- 与此同时,各类业务定制监控需求也开始全面铺开,使得监控方向日趋完备。
- 在上述基础能力不断迭代的过程中,需要运维、研发同学关注的事件也越来越多,因此整合监控能力,智能定位根因将是接下来监控方面的重要思路。
InfoQ:从以往滴滴出行的运维经历来看, 故障可以分为哪几类?
张云柳:故障方面,稳定性最大的敌人还是变更操作。目前变更引起的业务故障占比最多,主要包括手动操作、检查点不够完备以及高峰期操作等变更问题导致业务故障。针对这类变更问题,滴滴主要建立明确的规范、同时通过平台的技术保障规范的强制执行。其次是依赖的第三方服务故障导致业务受影响,对于该类问题加强多方联系沟通,建立日常协作保障机制,沟通解决方案,落实联动演练。最后是业务逻辑 bug、内部基础设施故障、服务隔离不合理等原因造成故障。
InfoQ:在 CNUTCon 全球运维技术大会上,你会重点为参会者分享哪些技术点?
张云柳:本次大会重点是给大家分享下滴滴在稳定性建设上的一些实践,主要是以下几点:
- 稳定性技术竞赛推进稳定性建设。 因为稳定性建设除基础的技术能力外,各团队的有效协作也是非常重要的点。所以首先给大家分享的是整个公司层面的稳定性技术竞赛,将会为大家分享滴滴稳定性建设如何做到全员参与?故障现场如何有组织、有纪律地救火。
- 从技术层面看故障的发现、定位、止损。该话题比较大,有如下几个细分方向:
- 从业务角度定义故障,智能诊断业务问题。各个系统级的故障比较常见,子系统故障不代表最终用户看到的业务是受损的。因此滴滴从用户的角度出发,定义各个产品线的重点业务指标,并采用预测算法等手段进行故障的智能发现。
- 基础监控能力建设,故障处理最佳流程梳理。监控能力将给大家介绍滴滴现有的整体监控建设情况,并详细分享上面提到的监控基础技术数据采集、实时聚合、数据存储及异常检测智能化等技术体系的建设以及其中遇到的教通用的数据处理问题。
- 事件统一收敛,智能定位探索。目前我们对报警类及操作类事件进行统一收敛,形成事件库。初步以 timeline 的方式展现便于大家发现可能的相关事件。另外在智能定位上基于时间、底层事件优先等规则进行的小规模实践也逐一分享给大家。