数字化运营基础技能 – pandas实战 – 数据清洗
这篇文章我会先给你讲解数据清洗的重要性,然后我会跟你列举数据清洗的四大准则,最后,我会用一个实战案例带你学会如何使用Python进行数据清洗。
也可以直接访问我的Github地址进行下载:
好了,接下来,咱们详细看一看。
认识数据清洗
数据清洗是数据分析过程中很重要的一个环节,将会占据50%以上的时间。
可以说,没有高质量的数据清洗就没有高质量的数据分析。
在不准确的数据基础上做出的分析,结论将变得毫无价值意义。
在数据分析前,我们要养成良好的数据审核习惯,保持对数据的敏锐性,这将会使你成为越来越优秀的数据分析师。
数据清洗四大准则
下图是数据科学家总结出的数据分析的四大准则,你可以记成完全合一,这样比较不容易忘记。
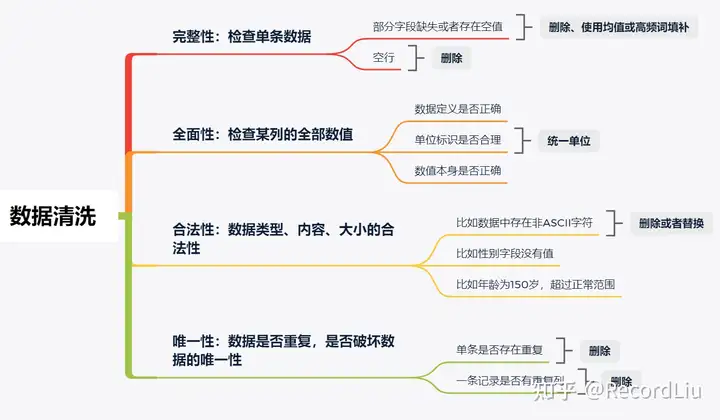
完全合一,即数据的完整性、全面性、合法性以及唯一性。
使用Python进行数据清洗
数据清洗有很多工具,市面上使用比较多的有Excel,Tableau Prep Builder、Python等。
这篇文章我主要给大家介绍使用Python进行数据清洗。
如果平常清洗工作不复杂,使用几行Python代码就能搞定清洗任务。
对于数据分析来说,花一些时间来学习Python是特别重要的。Python不仅在数据分析领域应用广泛,还能实现自动化办公,解放重复性工作,提高你的工作效率,这样省出的时间就能用来做对自我提升更有帮助的事情。
Python中进行数据清洗的工具是Pandas。
接下来我会介绍如果使用Pandas来清洗数据。
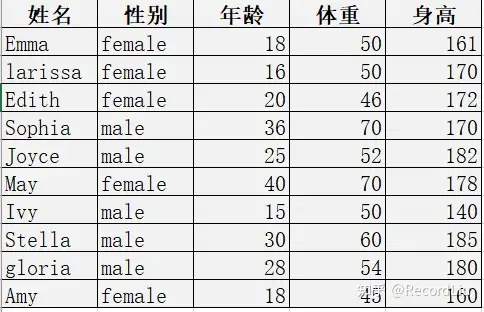
假设有一份会员数据,需要你做数据清洗,原始数据是这样的:
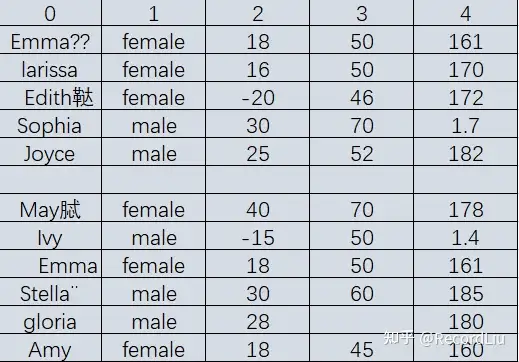
利用上面我们讲的”完全合一”准则,你从中发现几个问题?
我来解释一下数据的意义,第一列代表会员的姓名,第二列是性别,第三列是年龄,第四列是体重,第五列是身高。
使用完全合一准则来检查数据,我们可以发现以下问题:
1.列名为数字,不能知道具体的数据的含义
2.数据的完整性检查
- 发现案例有一整行记录为空值
- 姓名为gloria的体重数据缺失
3.数据的全面性检查
- 发现身高的度量单位不统一,有米的,也有厘米的
- 姓名的首字母大小写不统一,有大写,也有小写的
4.数据的合法性检查
- 年龄字段存在负数
- 性别字段存在非ASCII码字符、存在?号非法字符、出现空值
5.数据的唯一性检查
- 姓名为Emma的记录存在重复
针对以上问题,我们一般的解决办法为:
- 整行记录为空值,可以删除空行
- 空值可以使用体重列的平均值进行填充
- 统一身高的度量单位为米
- 统一姓名的首字母为大写
- 处理年龄字段负数为正数
- 删除姓名中存在的ASCII值、空值、?号非法字符
- 删除姓名为Emma的重复记录,只保留其中的一条
接下来,我们看一下使用Python是如何处理这些问题的:
第一步,我们需要安装Pandas库,在机器终端执行以下命令:
pip install pandas
第二步,在代码中引入pandas:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series,DataFrame
pandas中用于数据清洗和统计主要是基于Series,DataFrame两种数据结构。
第三步,从excel中加载数据到DataFrame中,我们使用pd.read_excel方法:
df = DataFrame(pd.read_excel('./data.xlsx'))
第四步,对列进行重命名,我们使用df.rename方法:
df.rename(columns={0:'姓名',1:'性别',2:'年龄',3:'体重',4:'身高'},inplace=True)
第五步,对整行为空值的数据进行删除,我们使用df.dropna方法:
df.dropna(how='all',inplace=True)
第六步,使用平均值来填充体重缺失的值,我们使用df.fillna方法:
df[u'体重'].fillna(int(df[u'体重'].mean()),inplace=True)
第七步,对身高列的度量做统一,我们使用df.apply方法来统一身高的度量,使用df.columns.str.upper方法将首字母统一为大写:
def format_height(df):
if(df['身高'] < 3):
return df['身高'] * 100
else:
return df['身高']
df['身高'] = df.apply(format_height,axis=1)
#2.姓名首字母大小写不统一,统一成首字母大写
df.columns = df.columns.str.upper()
第八步,对姓名列的非法字符做过滤,我们可以使用df.replace方法,删除字母前面的空格,我们可以使用df.map方法:
#1.英文名字出现中文->删除非ASCII码的字符
df['姓名'].replace({r'[^\x00-\x7f]+':''},regex=True,inplace=True)
#2.英文名字出现了问号->删除问号
df['姓名'].replace({r'\?+':''},regex=True,inplace=True)
#3.名字前出现空格->删除空格
df['姓名'] = df['姓名'].map(str.lstrip)
第八步,将年龄列为负值的年龄处理为正数,我们可以使用df.apply方法:
#4.年龄出现了负数->负数转化成正数
def format_sex(df):
return abs(df['年龄'])
df['年龄'] = df.apply(format_sex,axis=1)
第九步,删除行记录重复的数据,我们可以使用df.drop_duplicates方法:
df.drop_duplicates(['姓名'],inplace=True)
最后,我们讲清洗好的数据保存至新的excel中,我们可以使用df.to_excel方法:
df.to_excel('./data02.xlsx',index=False)
清洗后的最终数据如下图: