数字化运营基础技能 – 数据清洗实战:使用pandas清洗亚马逊电商销售数据
数据准备
清洗的是一份亚马逊黑色星期五电商节的销售数据,数据保存在 Excel 文件中
数据解释
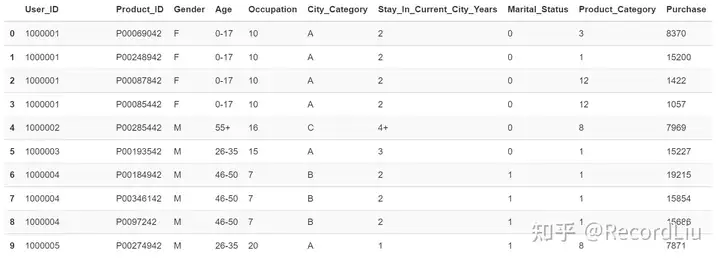
先来看一下表里面的前 10 行数据:
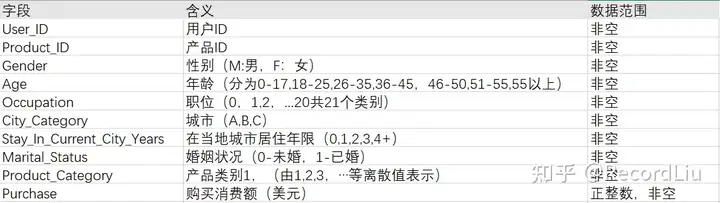
以下是每个数据列的含义以及数据范围:
接下来,我们来详细看一看数据清洗的过程。
清洗过程
1.将 Excel 转化成 Pkl 格式文件
清洗的第一步是要将 Excel 表格中的数据加载到 Pandas 中,由于这份数据较大,加载的速度非常缓慢,于是水哥针对这个问题做了下优化,大家可以看这篇文章:
RecordLiu:pandas加载大Excel文件缓慢问题优化2 赞同 · 4 评论文章
主要的优化思路就是把 Excel 文件转化成 Pkl 文件保存,然后再读取,这样能使 Pandas 读取大文件的速度变得特别快。
2.了解数据概况
在清洗数据前,我们需要了解数据的整体概况,比如数据的总数是多少、有多少缺失值、有多少重复值、有没有异常值、列值的一个分布情况等,我们将这一步称为「探索性数据分析」 (EDA)。
这一步水哥选用的是 pandas_profiling 这个模块,它很合适作为 EDA 的工具。
提示:水哥建议大家使用 anaconda 来安装 pandas_profiling 模块,如果使用
pip install的方式,很可能会碰到一些比较难解决的环境依赖问题。大家安装完 anaconda 后,在终端执行conda install pandas-profiling即可安装该模块。
接下来,我们使用 pandas_profiling 来简单生成一个数据分析报告。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import pandas as pd
import pandas_profiling
data = pd.read_pickle('./黑色星期五数据.pkl')
pfr = pandas_profiling.ProfileReport(data)
pfr.to_file("./黑色星期五数据概览.html")
解释下上面代码含义:
前两行的注释,第一行表示告诉编译器是 Python3 的运行环境,第二行表示文件编码类型为 utf-8。
接着,我们需要在文件的开头引入 pandas 和 pandas_profiling 模块。 然后通过 pandas 的 read_pickle 方法把数据源读到 data 中保存,再调用 pandas_profiling 模块的 ProfileReport 方法将 data 传过去生成一份数据分析报告。
最后调用 pandas_profiling 模块的 to_file 方法将报告保存到 html 文件中,这样我们就可以在浏览器访问到这份报告了。
提示:大家可以把 ProfileReport 方法理解成一个 「黑盒子」。我们不用关注这个黑盒子具体是怎么实现的,但它有一个 「魔法」,就是 「喂给它」我们想要分析的数据,就会给我们生成一份简易的数据分析报告。
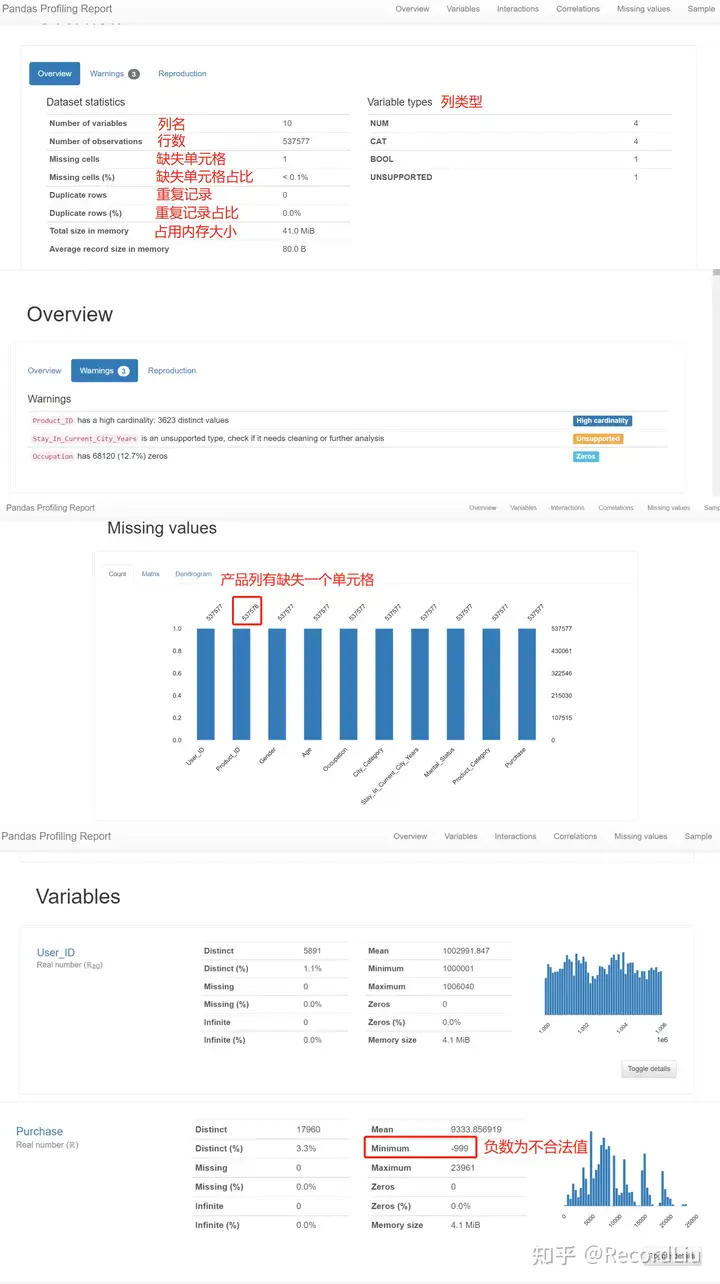
我们来看看最终生成的报告效果:
3.数据清洗的 3 个准则
水哥给大家总结了数据清洗的 3 个准则,分别是行准则、列准则、以及重复记录的检查:
RecordLiu:数据清洗都有哪些准则?0 赞同 · 0 评论文章
所以对于这份亚马逊销售数据的清洗,我们需要重点关注是,行记录的缺失情况、每个列值的合法性检查以及重复记录。
结合 pandas_profiling 生成的报告我们可以检查出:
- Product_ID 列具有一个空值,我们需要删除
- Purchase 列数据范围必须为正整数,从列值分布情况看出,最小值有 -999,为不合法的值,有负数的记录我们需要做删除
- 数据没有重复记录,因此不需要做任何处理
4.删除空值记录
我们将使用 DataFrame 的 dropna 函数来删除 Product_ID 为空值的行,代码如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series,DataFrame
#读取数据
df = DataFrame(pd.read_pickle('./黑色星期五数据.pkl'))
#删除 Product_ID 为空值的数
df.dropna(axis=0,how='any', inplace=True)
水哥给大家说明下 dropna 函数的用法:
- axis: 设置为
axis=0时,表示逢空值删除整行,设置为axis=1时,表示逢空值删除整列 - how: 设置成
how=any时,表示一行或者一列,有一个空值就删除整行或者整列,设置成how=all时,表示需要全部值为空值时才删除整行或者整列 - inplace: 设置成
True时,修改才能生效,源数据的空值才能删除
我们想要在 Product_ID 列为空值时,删除掉整行记录,所以 axis 需要设置成 0,how 需要设置成 any,并且需要让修改生效,inpalce 需要设置成 True。
5.删除负值记录
我们使用 DataFrame 的 drop 函数来删除 Purchase 列为负数的记录,代码如下:
# 删除 Purchase 为负数的记录
for x in df.index:
if df.loc[x, "Purchase"] < 0:
df.drop(x, inplace = True)
上面代码实现的功能为,使用for in语句来遍历每一行数据,再判断每行的Purchase列的值,如果值小于 0,则把该行进行删除。其中 loc表示坐标,是用来定位某一个单元格值的,df.loc[x,y] 表示的是第 x 行第 y 列单元格的值。
6.保存数据
最后,我们将清洗后的数据保存至 Excel 表格中,代码如下:
df.to_excel('./清洗完成数据.xlsx',index = False)
7.代码下载
本文中的代码示例水哥都上传到了 Github 上,需要的朋友可以自行下载。

github地址:
总结
在数据清洗前,我们可以使用一些 EDA 工具进行「探索性数据分析」,本文给大家介绍的是 pandas_profiling 这个第三方模块。通过 EDA 工具,我们可以清楚地知道数据的整体概况,有多少缺失值、数据的重复情况以及列值的分布、异常情况等,相当于给我们提供一个「全局的数据视角」,这样我们就可以有针对性地用 Pandas 来做数据清洗。
网站推荐
数据源获取
转行数据分析师,没有相关工作经验怎么办?方法是可以用做过的数据分析项目来弥补。
当我们用一些商业数据源来做分析时,就能比较贴合实际的工作场景,在此基础上做出分析项目,是有含金量的,面试官也会比较看重。
对于数据源的获取,一种方式是可以通过爬虫获取,比如用第三方工具或者用 Python 采集,那除了爬虫外,有没有一些免费的数据源获取呢?
水哥这里给大家推荐三个网站,分别是:和鲸社区、阿里云天池、kaggle。
这些网站不仅能获取到商业的数据源,还能看到别人的分析项目,也可以在上面做练习、打比赛,还有各种官方推荐的活动,也能和其他数据分析者进行交流,功能非常丰富。
网站直达:
- 和鲸社区:https://www.heywhale.com/home/dataset
- 阿里云天池:https://tianchi.aliyun.com/dataset
- kaggle:https://www.kaggle.com/datasets
学习网站
Python 和 SQL 的学习水哥推荐菜鸟教程网站推出的课程。菜鸟教程推出的课程一直是水哥学习编程语言时的首选,内容不仅基础全面,而且例子丰富,很具备实操性,可以当作手册来使用。
- SQL 教程:https://www.runoob.com/sql/sql-tutorial.html
- Python3 教程:https://www.runoob.com/python3/python3-tutorial.html
- Numpy 教程:https://www.runoob.com/numpy/numpy-tutorial.html
- Pandas 教程:https://www.runoob.com/pandas/pandas-tutorial.html
- Matplotlib 教程:https://www.runoob.com/matplotlib/matplotlib-tutorial.html
- SciPy 教程:https://www.runoob.com/scipy/scipy-