阿里大模型通义千问开源
从官网中介绍,通义千问有以下几个优点:
- 训练时使用了大规模的高质量数据:使用了超过2.2万亿token进行预训练
- 更好地支持多语言:基于更大词表的分词器在分词上更高效,同时它对其他语言表现更加友好。用户可以在Qwen-7B的基础上更方便地训练特定语言的7B语言模型。
- 支持8K长度上下文:允许用户输入更长的prompt。
- 评测能力有大幅提升:通义千问在多个评测数据集上具有显著优势,甚至超出12-13B等更大规模的模型。
从实验中看出,通义千问模型在多个数据集评测上都超过现有的开源模型,而且甚至比之前META开源的LLAMA2-7B模型效果要好:
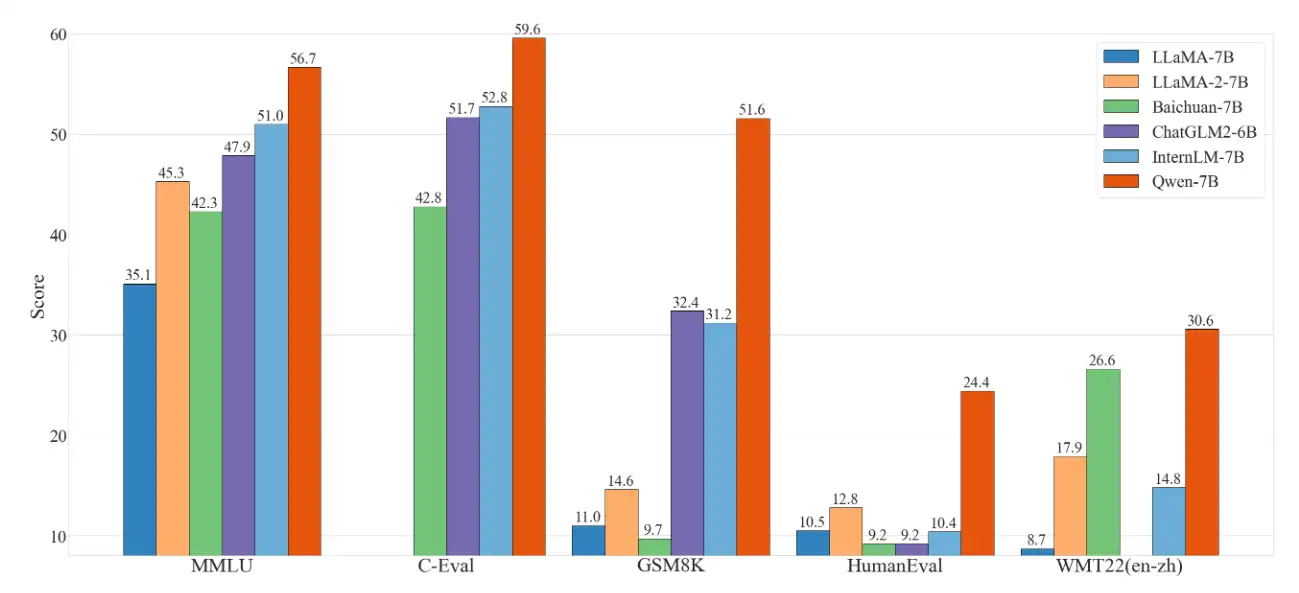
模型测评(对比GPT4)
代码调用中,只需要通过使用huggingface就可以搭建推理模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
# 请注意:分词器默认行为已更改为默认关闭特殊token攻击防护。相关使用指引,请见examples/tokenizer_showcase.ipynb
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
# 打开bf16精度,A100、H100、RTX3060、RTX3070等显卡建议启用以节省显存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# 打开fp16精度,V100、P100、T4等显卡建议启用以节省显存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
# 使用CPU进行推理,需要约32GB内存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
# 默认使用自动模式,根据设备自动选择精度
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True).eval()
# 可指定不同的生成长度、top_p等相关超参
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
# 第一轮对话 1st dialogue turn
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
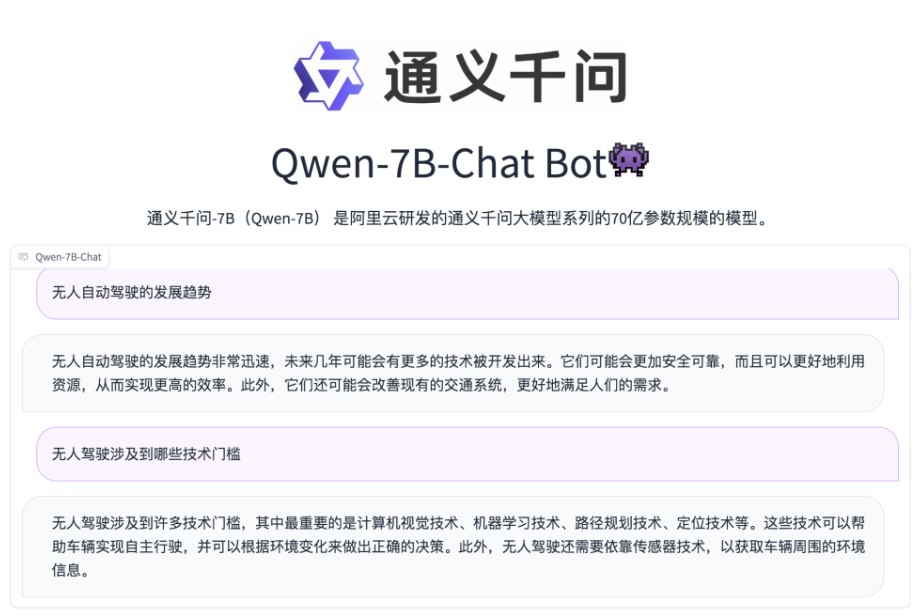
# 你好!很高兴为你提供帮助。Q1:什么工作钱多事少离家近?
通义千问:教师、护士、零售员工、客服。在这个回答中,前面两个答案还可以,但是后面的答案像是随机生成的,并不符合我的提问要求。
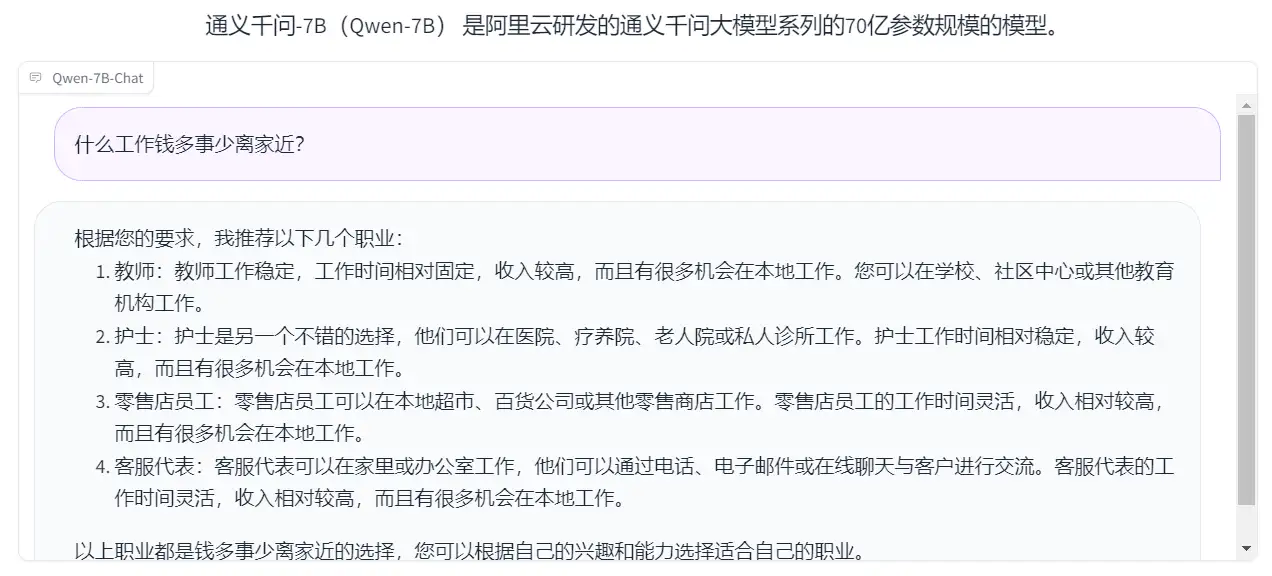
Bing:保险代理人、程序员、翻译、市场营销
阿里云开源了QWen-7B 和QWen-7B-Chat模型。在多个权威测评中,通义千问7B模型都取得了远超国内外同等尺寸模型的效果,成为当下业界最强的中英文7B开源模型!目前,两个模型均已在AI模型社区「魔搭ModelScope」上线,开发者们可直接下载和使用魔搭提供的sft脚本进行微调~ 本期视频,我们就一起来看下如何使用这两个模型叭!
# 开源地址
魔搭ModelScope
https://modelscope.cn/models/qwen/Qwen-7B/summary
https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary
Hugging Face
GitHub
https://github.com/QwenLM/Qwen-7B
# Qwen-7B
https://modelscope.cn/models/qwen/Qwen-7B/summary
通义千问-7B(Qwen-7B) 是阿里云研发的通义千问大模型系列的70亿参数规模的模型。Qwen-7B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在Qwen-7B的基础上,我们使用对齐机制打造了基于大语言模型的AI助手Qwen-7B-Chat。本仓库为Qwen-7B的仓库。
通义千问-7B(Qwen-7B)主要有以下特点:
- 大规模高质量训练语料:使用超过2.2万亿tokens的数据进行预训练,包含高质量中、英、多语言、代码、数学等数据,涵盖通用及专业领域的训练语料。通过大量对比实验对预训练语料分布进行了优化。
- 强大的性能:Qwen-7B在多个中英文下游评测任务上(涵盖常识推理、代码、数学、翻译等),效果显著超越现有的相近规模开源模型,甚至在部分指标上相比更大尺寸模型也有较强竞争力。具体评测结果请详见下文。
- 覆盖更全面的词表:相比目前以中英词表为主的开源模型,Qwen-7B使用了约15万大小的词表。该词表对多语言更加友好,方便用户在不扩展词表的情况下对部分语种进行能力增强和扩展。
# Qwen-7B-Chat
https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary
通义千问-7B(Qwen-7B) 是阿里云研发的通义千问大模型系列的70亿参数规模的模型。Qwen-7B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在Qwen-7B的基础上,我们使用对齐机制打造了基于大语言模型的AI助手Qwen-7B-Chat。本仓库为Qwen-7B-Chat的仓库。
# 模型细节 (Model)
Qwen-7B模型规模基本情况如下所示:
| Hyperparameter | Value |
|---|---|
| n_layers | 32 |
| n_heads | 32 |
| d_model | 4096 |
| vocab size | 151851 |
| sequence length | 2048 |
在位置编码、FFN激活函数和normalization的实现方式上,我们也采用了目前最流行的做法, 即RoPE相对位置编码、SwiGLU激活函数、RMSNorm(可选安装flash-attention加速)。
在分词器方面,相比目前主流开源模型以中英词表为主,Qwen-7B使用了超过15万token大小的词表。该词表在GPT-4使用的BPE词表cl100k_base基础上,对中文、多语言进行了优化,在对中、英、代码数据的高效编解码的基础上,对部分多语言更加友好,方便用户在不扩展词表的情况下对部分语种进行能力增强。词表对数字按单个数字位切分。调用较为高效的tiktoken分词库进行分词。
我们从部分语种各随机抽取100万个文档语料,以对比不同模型的编码压缩率(以支持100语种的XLM-R为基准值1,越低越好),具体性能见图。
可以看到Qwen-7B在保持中英代码高效解码的前提下,对部分使用人群较多的语种(泰语th、希伯来语he、阿拉伯语ar、韩语ko、越南语vi、日语ja、土耳其语tr、印尼语id、波兰语pl、俄语ru、荷兰语nl、葡萄牙语pt、意大利语it、德语de、西班牙语es、法语fr等)上也实现了较高的压缩率,使得模型在这些语种上也具备较强的可扩展性和较高的训练和推理效率。
在预训练数据方面,Qwen-7B模型一方面利用了部分开源通用语料, 另一方面也积累了海量全网语料以及高质量文本内容,去重及过滤后的语料超过2.2T tokens。囊括全网文本、百科、书籍、代码、数学及各个领域垂类。
# Demo
https://modelscope.cn/studios/qwen/Qwen-7B-Chat-Demo/summary