经验教训 – 生产环境血的教训最佳实践
每一条教训都是通过生产环境异常总结出来经验
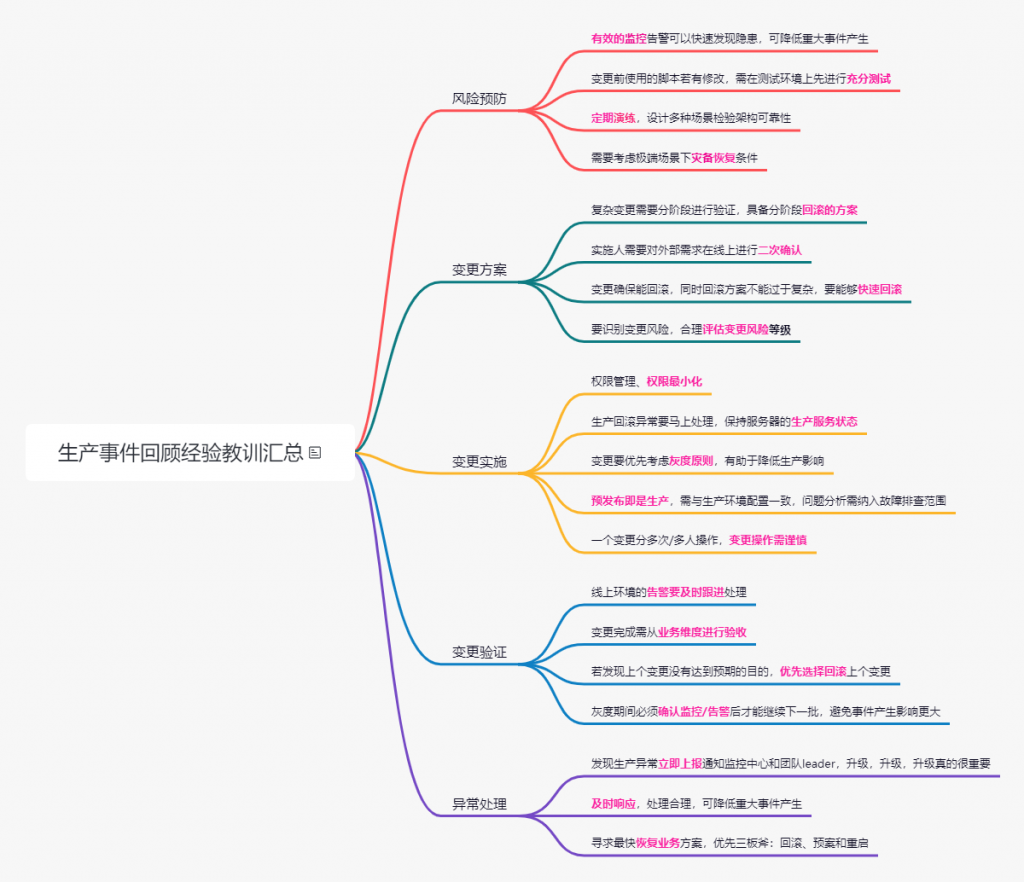
教训1: 变更实施 – 变更要优先考虑灰度原则,有助于降低生产影响
教训2:变更实施 – 生产回滚异常要马上处理,保持服务器的生产服务状态
教训3:变更验证 – 灰度期间必须确认监控/告警后才能继续下一批,避免事件产生影响更大
教训4:变更验证 – 变更完成需从业务维度进行验收
教训5:变更实施 – 预发布环境即是生产环境,需与生产环境配置保持一致
教训6:变更实施 – 一个变更分多次/多人操作,变更风险需谨慎
教训7:变更验证 – 若发现上个变更没有达到预期的目的,优先选择回滚上个变更
教训8: 变更验证 – 线上环境的告警要及时跟进处理
教训9:风险预防 – 有效的监控告警可以快速发现隐患,可降低重大事件产生
教训10:异常处理 – 寻求最快恢复业务方案,优先三板斧:回滚、预案和重启
教训11:变更方案 – 实施人需要对外部需求在线上进行二次确认
教训12:变更方案 – 复杂变更需要分阶段进行验证,具备分阶段回滚的方案
教训13:变更实施 – 权限管理、权限最小化
教训14:异常处理 – 发现生产异常立即上报通知监控中心和团队leader,升级,升级,升级真的很重要
教训15:风险预防 – 需要考虑极端场景下灾备恢复条件
教训16:风险预防 – 回滚方案不能过于复杂,要能够快速回滚
教训17:异常处理 – 及时响应,处理合理,可降低重大事件产生
教训18:变更实施 – 要识别变更风险,合理确定变更风险等级
教训19:风险预防 – 变更前使用的脚本若有修改,需在测试环境上先进行充分测试
教训20:风险预防 –定期演练,设计多种场景检验架构可靠性,同时能够增强员工在故障处理情况下的信心
业界运维经验
日常运维:
1.无监控不运维,必须确保系统、应用、日志等已有监控与告警
2.稳定大于一切,必须有高度责任心,主人翁精神
3.交接和休假最容易出故障,交接内容必须当面或电话沟通确认,变更请谨慎
4.生产证书有效期必须加以监控
5.对生产环境永保敬畏之心,提高重视程度,往往都是小变更出现故障
6.oncall电话必须保持24小时开机
7.在重要操作之前一定要看自己所在的机器,尽量避免多开窗口
8.确保变更可以回滚
9.批量操作前,必须先灰度再全量
10.若发现上个变更没有达到预期的目的,优先选择回滚上个变更
11.生产异常必须升级反馈
12.生产回滚异常要马上处理,保持服务器的生产服务状态
13.变更完成必须及时做操作验证与业务验证
14.寻求最快恢复业务方案,优先三板斧:回滚、预案和重启
15.刨根问底,偏执一点,分析,分析,再分析;每个偶然的故障背后都深藏着必须的联系,找到问题根源并优化掉
16.测试环境与生产环境配置链接不能同一个域名,生产操作需关闭所有窗口后,再进行生产操作
17.简单即是美
安全运维
1.防火墙生产环境一定要开,并且要遵循最小原则,drop所有,然后放行需要的服务端口。
2.精细权限和控制粒度,运维人员的权限进行分级,离职转岗应及时清理
3.停用或关闭无用的服务,系统服务最小化
4.重要密码一定不能同其它互联网帐号密码相同
5.运行的业务进程尽不要输出敏感信息到日志文件中,避免代码打印数据库连续帐号信息
6.SSH等远程登录一定要限制访问IP或限制跳板机IP
数据库运维
1.数据安全是底线,即使不服务也不能丢数据
2.备份大于一切,备份系统自动化,中心化调试,保障故障效率和可用性
3.对不可逆的删除或修改操作,保持慢速执行,Enter前再三确认
4.不同年限的设备性能不同,磁盘读写能力不一致,要区别对待,老化磁盘要定期淘汰
5.数据库要具备限流能力
6.做好日常数据库容量度量,用历史数据推算下一个容易高峰,避免常规节假日、促销等容量不足
自动化运维
1.自动化运维的终极目标是消息SecureCRT等一切远程客户端
2.你不用造轮子,可以先考虑开源方案加二次开发满足运维需求
3.安全必须是内置在自动化运维中的,通过主动发现和深度防御机制保障安全
4.自动化运维的底层必须保证完整性,技术手段与流程保障并行
5.以自动探测和上报提高 CMDB配置的效率和维护数据准确性
6.监控体系的自动化是整个体系的钮带,它贯穿着事件和故障自愈