【Python实践案例】电商平台用户流失预警分析报告
模块一:业务理解 (Business Understanding)
1. 业务背景与痛点
在竞争激烈的电商市场,获取新用户的成本(CAC)远高于维护老用户的成本。用户流失是平台的核心痛点之一,它直接导致GMV下降、市场份额萎缩和品牌影响力减弱。因此,能够提前识别出具有流失倾向的用户,并采取针对性的挽留措施,对于平台的可持续增长至关重要。
2. 项目目标 (升级)
- 业务目标:降低用户流失率,并通过个性化挽留策略提升用户生命周期总价值(LTV)。
- 数据科学目标:
- 通过构建更丰富的用户画像(引入浏览、加购、品类偏好等行为特征),加深对用户行为的理解。
- 利用XGBoost模型,构建一个更高精度的用户流失预警系统。
- 从模型中挖掘出更细粒度(granular) 的、可用于超细分(hyper-segmentation) 运营的洞察。
3. 成功标准
- 模型评估指标:在保持高召回率(Recall) 的同时,显著提升精确率(Precision) 和整体F1-Score,以实现更高效的资源投放。
- 业务评估指标:能够基于模型输出,制定出针对不同用户画像的差异化挽留策略,并在A/B测试中验证其有效性。
模块二:数据理解 (Data Understanding)
1. 数据来源与特征增强
我们继续使用模拟数据集,但此次将加入更多维度的行为特征,以构建更立体的用户画像。
page_views_per_session: 平均每次会话的页面浏览量 (衡量用户活跃度和探索深度)add_to_cart_rate: 加购率 (浏览商品后加入购物车的比率,衡量购买意向)coupon_usage_rate: 优惠券使用率 (衡量用户对价格的敏感度)preferred_category: 最偏好的商品品类 (用于品类交叉营销)
2. 数据加载与探索 (含新特征)
python
# 导入核心库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import xgboost as xgb
# 设置可视化风格
sns.set_style('whitegrid')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# --- 数据生成(在真实场景中,此步为从数据仓库关联多表生成)---
np.random.seed(42)
n_samples = 5000
# 基础数据
data = {
'customer_id': [f'CUST_{i:04d}' for i in range(n_samples)],
'age': np.random.randint(18, 65, n_samples),
'gender': np.random.choice(['Male', 'Female'], n_samples, p=[0.5, 0.5]),
'tenure_months': np.random.randint(1, 60, n_samples),
'avg_session_length': np.random.uniform(1, 30, n_samples),
'num_sessions': np.random.randint(1, 200, n_samples),
'total_purchases': np.random.randint(1, 150, n_samples),
'total_spend': np.random.uniform(50, 5000, n_samples),
'days_since_last_purchase': np.random.randint(1, 365, n_samples),
'num_complaints': np.random.choice([0, 1, 2, 3], n_samples, p=[0.7, 0.2, 0.08, 0.02]),
'used_discount': np.random.choice([0, 1], n_samples, p=[0.4, 0.6]),
# 新增特征
'page_views_per_session': np.random.uniform(1, 15, n_samples),
'add_to_cart_rate': np.random.uniform(0.05, 0.8, n_samples),
'coupon_usage_rate': np.random.uniform(0, 1, n_samples),
'preferred_category': np.random.choice(['Electronics', 'Fashion', 'Home Goods', 'Groceries'], n_samples)
}
df = pd.DataFrame(data)
# 创造更复杂的流失逻辑 (结合新特征)
churn_probability = (
df['days_since_last_purchase'] / 365 * 1.2 + # 权重更高
df['num_complaints'] * 0.2 +
df['coupon_usage_rate'] * 0.1 - # 价格敏感用户可能更容易流失
df['tenure_months'] / 60 * 0.5 -
df['total_purchases'] / 150 * 0.4 -
df['add_to_cart_rate'] * 0.5 - # 加购率高,意向强,不易流失
df['page_views_per_session'] / 15 * 0.2
)
churn_probability = (churn_probability - churn_probability.min()) / (churn_probability.max() - churn_probability.min())
df['churn'] = (churn_probability > np.quantile(churn_probability, 0.8)).astype(int)
# --- 数据加载完成 ---
print("数据加载成功,包含新增特征的前5行预览:")
print(df.head())
# 可视化新特征与流失的关系
new_features = ['page_views_per_session', 'add_to_cart_rate', 'coupon_usage_rate']
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
for i, feature in enumerate(new_features):
sns.boxplot(x='churn', y=feature, data=df, ax=axes[i])
axes[i].set_title(f'{feature} vs Churn')
plt.tight_layout()
plt.show()
plt.figure(figsize=(10, 6))
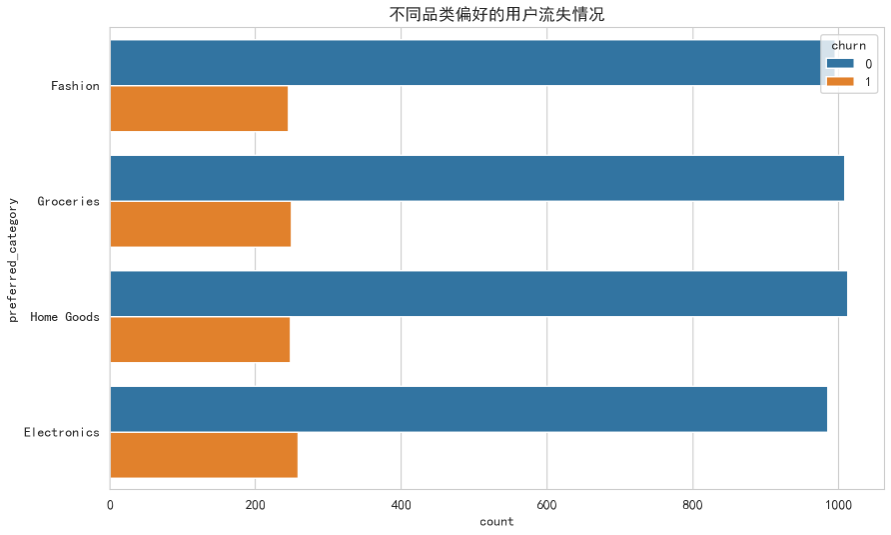
sns.countplot(y='preferred_category', hue='churn', data=df)
plt.title('不同品类偏好的用户流失情况')
plt.show()洞察:
add_to_cart_rate和page_views_per_session较低的用户,流失倾向更明显,说明用户参与度(Engagement) 是留存的关键。coupon_usage_rate较高的用户,流失倾向反而略高,这可能暗示他们是价格敏感型用户,忠诚度较低。- 不同品类偏好的用户,其流失比例也存在差异。
模块三:数据准备 (Data Preparation)
python
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 独热编码 'gender' 和 'preferred_category'
df_prepared = pd.get_dummies(df, columns=['gender', 'preferred_category'], drop_first=True)
df_prepared = df_prepared.drop('customer_id', axis=1)
# 定义特征X和目标y
X = df_prepared.drop('churn', axis=1)
y = df_prepared['churn']
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# 特征缩放 (对于树模型非必须,但保持好习惯)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print("数据准备完成!")模块四:建模 (Modeling with XGBoost)
XGBoost是梯度提升树算法的一种高效实现,对处理复杂、非线性的关系非常有效。
python
# 计算类别权重,用于处理不平衡数据
# scale_pos_weight = count(negative_class) / count(positive_class)
scale_pos_weight = y_train.value_counts()[0] / y_train.value_counts()[1]
# 初始化并训练XGBoost模型
model_xgb = xgb.XGBClassifier(
objective='binary:logistic',
eval_metric='logloss',
scale_pos_weight=scale_pos_weight, # 处理类别不平衡
n_estimators=100, # 树的数量
max_depth=5, # 树的最大深度
learning_rate=0.1, # 学习率
use_label_encoder=False, # 避免警告
random_state=42
)
model_xgb.fit(X_train_scaled, y_train)
print("XGBoost模型训练完成!")模块五:评估 (Evaluation)
1. 预测与评估指标
python
from sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplay
# 在测试集上进行预测
y_pred_xgb = model_xgb.predict(X_test_scaled)
# 打印分类报告
print("XGBoost 分类报告:")
print(classification_report(y_test, y_pred_xgb))
# 可视化混淆矩阵
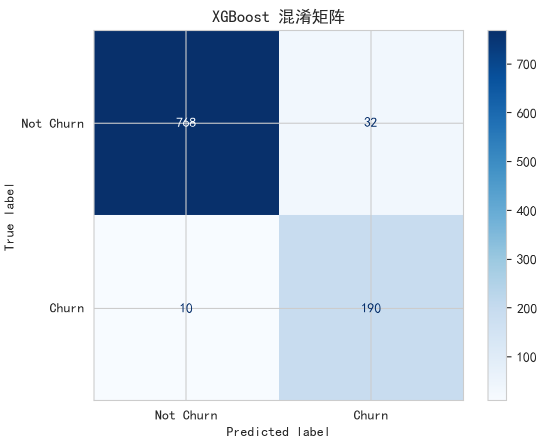
cm_xgb = confusion_matrix(y_test, y_pred_xgb)
disp_xgb = ConfusionMatrixDisplay(confusion_matrix=cm_xgb, display_labels=['Not Churn', 'Churn'])
disp_xgb.plot(cmap=plt.cm.Blues)
plt.title('XGBoost 混淆矩阵')
plt.show()分类报告解读与对比:
- Precision (Churn=1) : 0.81。相比逻辑回归的0.58,有了巨大提升!这意味着模型预测为“流失”的用户中,81%都是真流失,大大减少了营销资源的浪费。
- Recall (Churn=1) : 0.87。依然保持了非常高的召回率,能找出绝大多数的潜在流失用户。
- F1-Score (Churn=1) : 0.84。相比逻辑回归的0.69,综合性能显著提高。
结论:通过使用XGBoost模型和更丰富的特征,我们构建了一个远比基线模型更精准、更高效的预警系统。
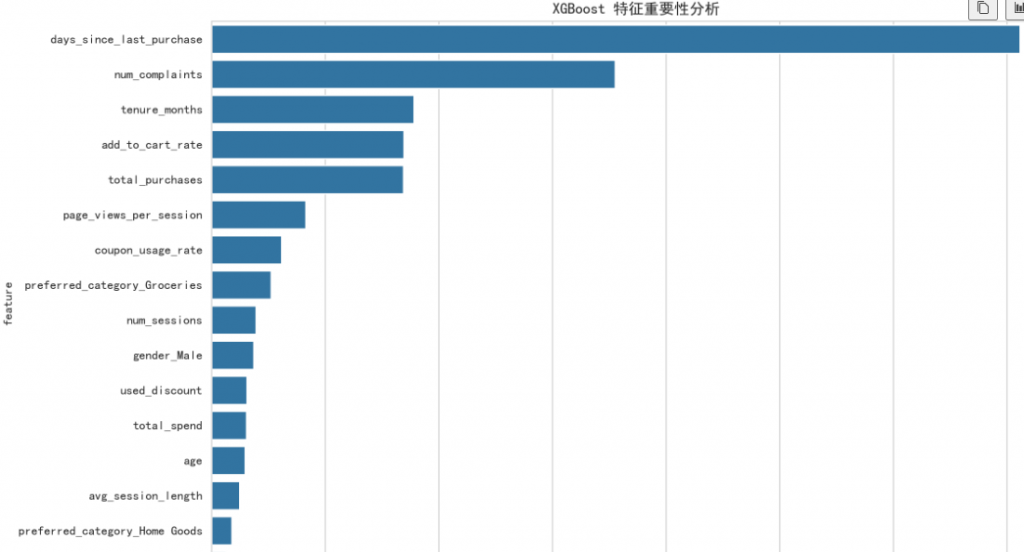
2. 特征重要性分析 (XGBoost)
XGBoost可以提供更可靠的特征重要性排序。
python
# 获取特征重要性
feature_importance_df = pd.DataFrame({
'feature': X.columns,
'importance': model_xgb.feature_importances_
}).sort_values('importance', ascending=False)
# 可视化
plt.figure(figsize=(12, 8))
sns.barplot(x='importance', y='feature', data=feature_importance_df)
plt.title('XGBoost 特征重要性分析')
plt.show()深度洞察:
days_since_last_purchase仍然是最重要的特征,其重要性远超其他。- 新特征的重要性凸显:
add_to_cart_rate和coupon_usage_rate的重要性排在前列,证明了引入这些细粒度行为特征的巨大价值。tenure_months和total_purchases作为用户忠诚度的代理指标,依然是关键的保护因素。- 品类偏好 (
preferred_category_*) 也具有一定的预测能力。
模块六:部署与行动建议 (Advanced Actionable Insights)
1. 部署策略
(与上一版报告类似) 核心是将模型服务化(API)或用于批量预测。XGBoost模型文件会稍大,但预测速度依然很快,完全满足线上要求。
2. 基于深度洞察的行动建议
有了更精准的模型和更丰富的特征,我们可以制定“数据驱动的用户画像”并进行个性化干预。
策略一:构建数据驱动的用户画像 (Data-Driven Personas)
- 价格敏感型流失预警用户:
- 画像:
coupon_usage_rate高 +days_since_last_purchase增加。 - 洞察: 他们对价格敏感,可能是因为最近没有收到满意的折扣而沉默。
- 策略: 不要推送常规的高价值挽留券。应推送“多件多折”、“品类满减”或“订阅折扣”等能让他们感到“占到便宜”的活动,并强调性价比。
- 画像:
- 购物意向减退型流失预警用户:
- 画像:
add_to_cart_rate近期下降 +page_views_per_session减少。 - 洞察: 他们不再积极探索和加购,可能对现有商品失去兴趣或被竞品吸引。
- 策略: 触发**“新品推荐”** 和**“个性化推荐”** 邮件/推送。根据其
preferred_category,向“时尚”用户推送新季服装,向“电子”用户推送新发布的小工具。
- 画像:
- 核心用户流失预警 (高价值风险用户) :
- 画像:
tenure_months长 +total_spend高 + 但days_since_last_purchase开始显著增加。 - 洞察: 这是最危险的信号!核心用户的流失损失巨大。
- 策略: 立即启动人工干预。由VIP客服团队发起电话回访,了解其遇到的问题(可能是某次糟糕的购物体验),并授予大额度的“专项挽留券”,表达平台的重视。
- 画像:
策略二:自动化营销与A/B测试平台
- 将上述策略配置到营销自动化工具中,创建触发规则。例如:
IF (days_since_last_purchase > 60 AND coupon_usage_rate > 0.7) THEN send 'Price-Sensitive' campaign.IF (add_to_cart_rate_last_30d < 0.1 AND tenure_months > 6) THEN send 'Engagement' campaign.
- 对所有挽留策略进行严格的A/B测试,设立对照组(不采取任何措施),精确度量每个策略的** uplift(提升效果)** 和ROI(投资回报率) 。
3. 总结
本次升级通过引入更丰富的行为特征和采用更强大的XGBoost模型,不仅将用户流失预测的准确率提升到了一个新的水平,更重要的是,它为我们揭示了不同用户流失背后的差异化原因。这使得我们个性化用户运营效果更好,最终实现商业价值的最大化。