系统稳定性保障 – 大厂故障演练思考
引言
阿里巴巴经过多年的技术演进,系统工具和架构已经高度垂直化,服务器规模也达到了比较大的体量。当服务规模大于10000台时,小概率的硬件故障每天都会发生。这时如果需要人的干预,系统就无法可靠的伸缩。为此每一层的系统都会面向失败做设计,对下游组件零信任,确保在故障发生时可以快速的发现和处理。
不过这些措施在故障发生时是否真的有效?恢复故障的工具是否实现了容灾?处理问题的人是否熟练?沟通机制是否疏漏?容灾措施的影响是否会辐射到上一层?这些问题,平时没有太多的机会验证,就是真的有问题,往往也是在真实故障中暴露。
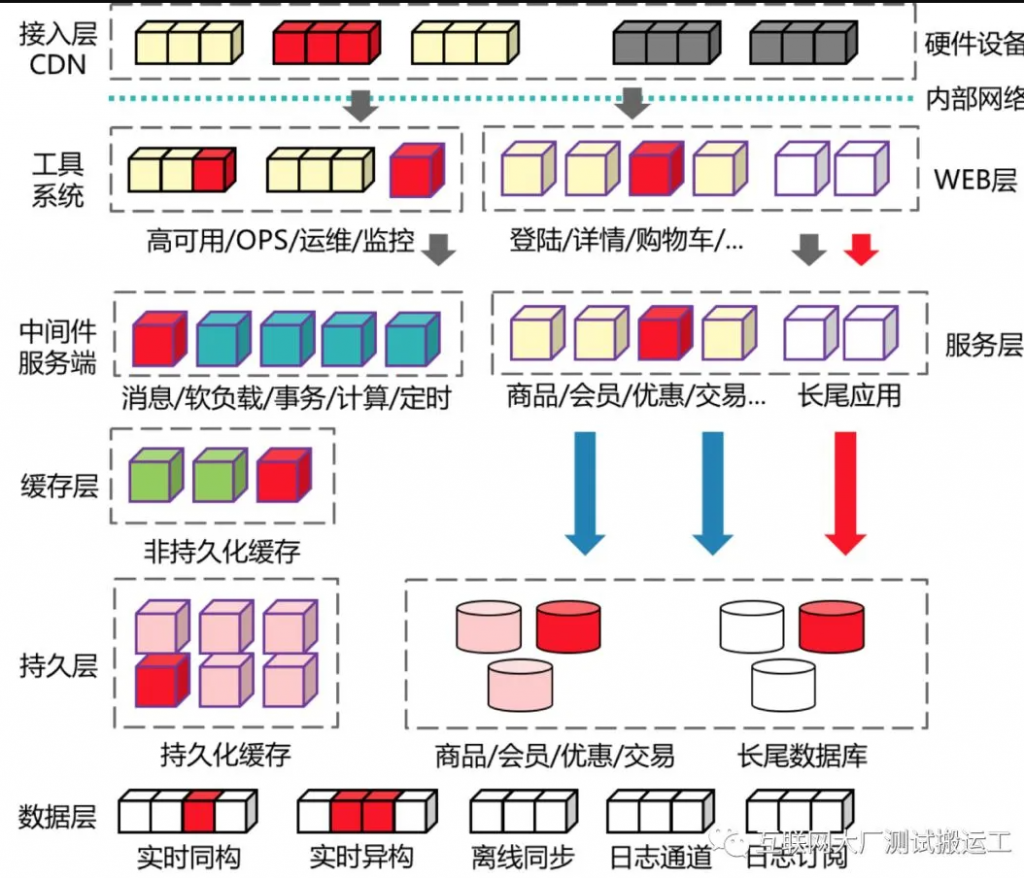
领域介绍
关于故障的思考
- 任何不符合预期状态的事件都可以称为问题。
- 任何基础设施、生产系统、人和流程都可能发生问题。当系统体量到达一定规模时,问题每天都在发生。
- 当问题不能被合理处理,产生业务级或全局性的影响时,问题将上升为故障。
- 任何故障都是独特的(如:发生时间地点、业务影响、处理流程),但是故障的成因(或场景)是可被枚举的。
故障演练的定义
线上故障演练就是通过平台化的方式沉淀通用的故障场景,以可控成本在线上故障重放,通过持续性的演练和回归方式来暴露问题,提升问题的响应和修复能力,缩短故障修复时长(MTTR)。
实施准备
对于一个准备实施或刚刚开始实施故障演练的团队,除了要掌握一些工具使用和实施策略,在文化建设、目标设定、风险控制和效率角度也要保持关注。
第一、引入混沌工程,需要建立面向失败设计和拥抱失败的文化
在思想上要认识到混沌工程的核心是通过引入一些实验变量去提前暴露已有问题,而不是创造问题。在恰当的时间和可控的爆炸半径下实施实验,有助于问题的发现和处理,降低潜在故障的影响。
传统的基础设施对于稳定性、健壮性有非常高的要求,虽然减少变更频率可以降低故障,但不是解决问题的根本方法。随着迁移到云上,基础设施的管理被转移到云厂商,上层的业务更需要做好面向失败设计,可以应对可能存在的极端情况。
第二、实施混沌工程,需要定义一个清晰可衡量的目标
混沌工程对于系统的可观察性有较高的要求。为了实施一次高质量的混沌工程实验,必须要对系统的稳态有清晰的定义。稳态指标最好能够体现客户的满意程度,业务指标好于系统指标,SLA或业务故障等级定义都是不错的选择。
混沌工程的业务价值并不适合用过程指标来度量,比如模拟了多少种实验场景、发起多少次实验等。推荐的方式是配合其他稳定性手段一起来衡量。比如:
初期:可以选择故障覆盖率这个指标(即发生并改进过故障的系统,要能够免疫同样原因的故障)。此时实验场景数就近似等同于故障覆盖率的分母。
中期:可以选择监控发现率这个指标。此时实验场景数与实验次数是分母,能够及时发现的次数(即触发稳态指标预警的次数)就是分子。
后期:随着混沌工程实施经验的丰富,可以考虑引入一些度量MTTR能力的指标项,比如发现-定位-恢复这种整体性指标。
第三、推广混沌工程,要在控制风险的同时不断提升效率
越贴近生产环境的实验,结果越真实,同时风险也越大。可以从一些简单的场景开始尝试,逐渐增加对系统和实验的信心。准备大于执行,要重点关注实验方案的评估,明确定义系统稳态和终止条件。
掌握混沌工程的思想,任何手段都可以成为实验的工具。当需要规模化推广和实施时,从开发成本和可维护性角度,可以考虑复用一些成熟的开源组件或商业工具。
实践策略
建立一个围绕稳定状态行为的假说
目前集团内的实践主要分为有两个方向:
- 第一类是偏向于测试(比如:故障注入测试),即在一个具体场景下实施故障注入实验并验证预期是否得到满足。这种测试的风险相对可控,坏处是并没有通过故障注入实验探索更多的场景,暴露更多的潜在问题,测试结果比较依赖实施人的经验。
- 第二类偏向于实验(比如:突袭演练),即在一个相对宽泛的业务背景下模拟一些可能发生的故障,除了观察系统和业务的表现,还会重点考察人员的应急能力及故障恢复有效性。
测试一般有固定的输入和输出,不会产生关于系统的新知识。而实验会产生新知识,并经常提出新的探索途径。从定性角度,我们更愿意把故障演练定性为一个实验行为。
对于稳态的设计,有一些推荐的策略:
- 观测可测量的输出,而不是系统内部的属性。
- 短时间的度量结果,代表了系统的稳定状态。
- 验证系统是否工作,而不是如何工作。
多样化真实世界的事件
阿里巴巴因为多元化的业务场景、规模化的服务节点及高度复杂的系统架构,每天都会遇到各式各样的故障。这些故障信息就是最真实的混沌工程变量。为了能够更体感、有效率的描述故障,我们优先分析了P1P2的故障,提出一些通用的故障场景并按照IaaS层、PaaS层、SaaS层的角度绘制了故障画像。
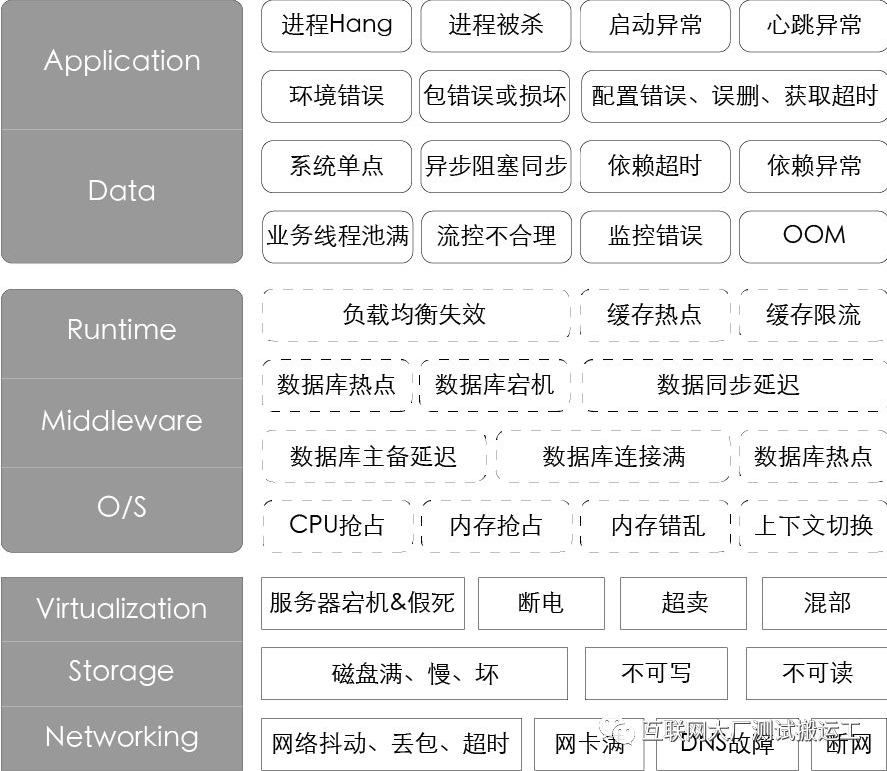
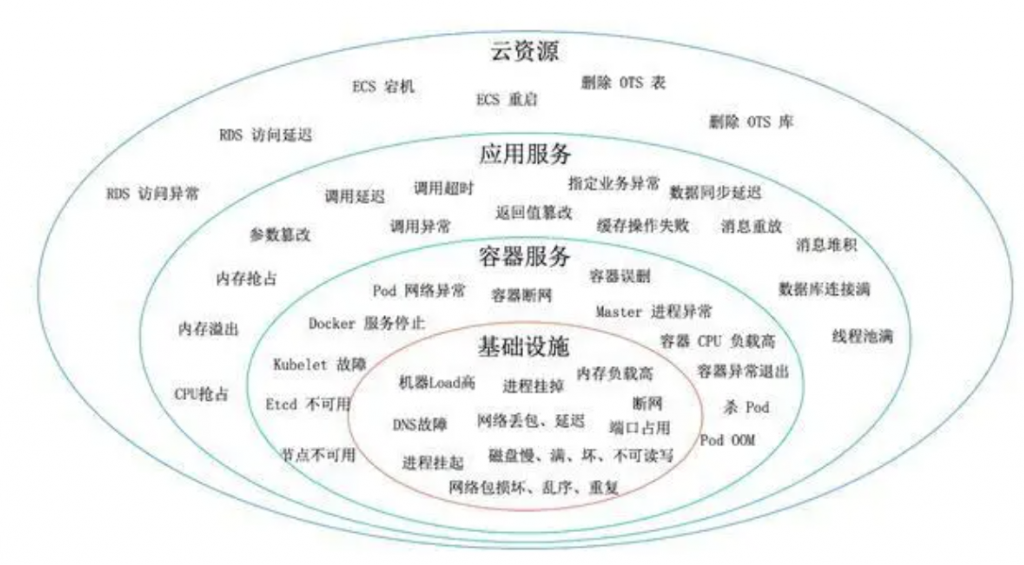
从故障的完备性角度,上述画像只能粗略代表部分已出现的问题,对于未来可能会出现的新问题我们也需要一种手段保持兼容。在更深入的进行分析之后,我们定义了另一维度的故障画像:
- 任何故障,一定是硬件如IaaS层,软件如PaaS或SaaS的故障。并且有个规律,硬件故障的现象,一定可以在软件故障现象上有所体现。
- 故障一定隶属于单机或是分布式系统之一,分布式故障包含单机故障。
- 对于单机或同机型的故障,以系统为视角,故障可能是当前进程内的故障,比如:如FullGC,CPU飙高;进程外的故障,比如其他进程突然抢占了内存,导致当前系统异常等。
- 同时,还可能有一类故障,可能是人为失误,或流程适当导致,这部分我们今天不做重点讨论。
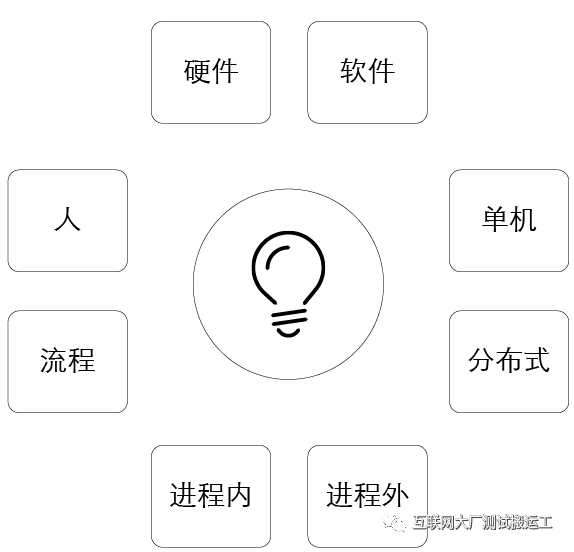
集团的故障演练就是参照上述场景来设计的,同时底层的故障模拟技术ChaosBlade已经对外开源。
在生产环境中运行实验
从功能性的故障测试角度,非生产环境去实施故障注入是可以满足预期的,所以最早的强弱依赖测试就是在日常环境完成的。不过因为系统行为会根据环境和流量模式有所不同,为了保证系统执行方式的真实性与当前部署系统的相关性,推荐的实施方式还是在生产环境(仿真环境、沙箱环境都不是最好的选择)。
很多同学恐惧在生产环境执行实验,原因还是担心故障影响不可控。实施实验只是手段,通过实验对系统建立信心是我们的目标。关于如何减少实验带来的影响,这点在”最小化爆炸半径”部分会有阐述。
持续自动化运行实验
一次完整的故障演练,可能会设计到方案梳理、故障注入、稳态观察、问题记录、还原和分析等。手动运行试验是劳动密集型的,最终是不可持续的,所以我们要把试验自动化并持续运行。构建自动化的编排和分析是演练工具要具备的基础能力。故障演练平台MonkeyKing目前实现了一套通用的编排方案,可以让用户结合实际需求进行扩展。
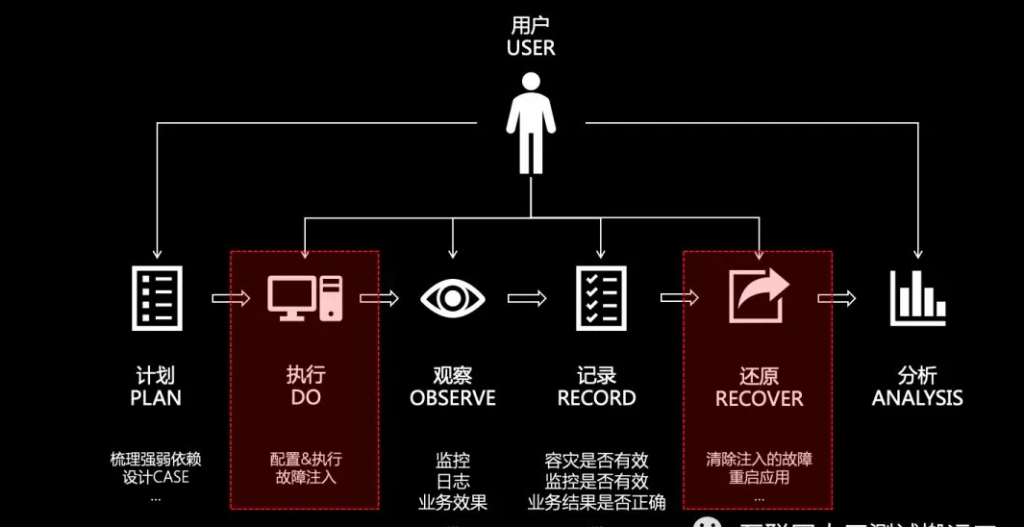
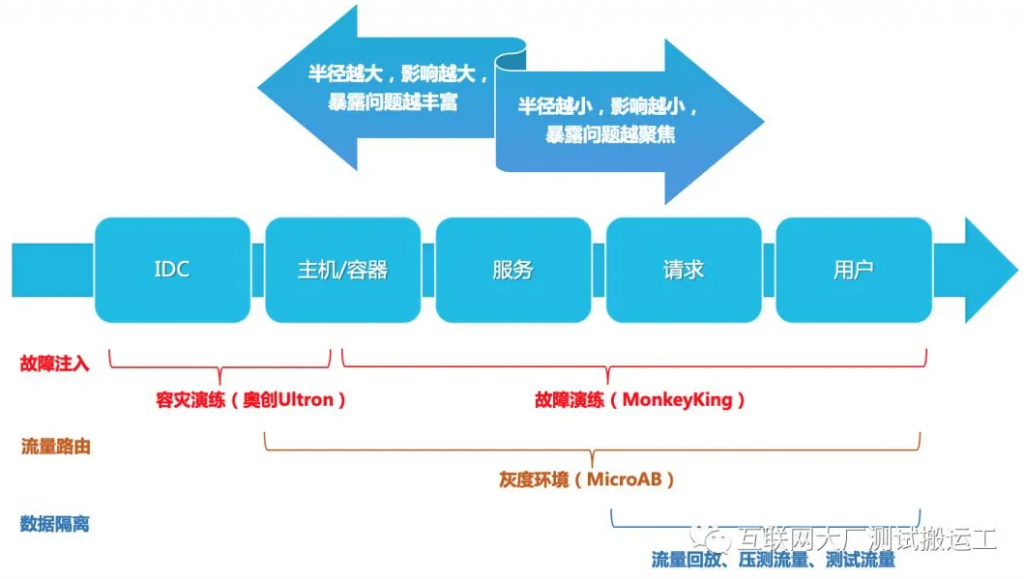
最小化爆炸半径
在生产中进行试验可能会造成不必要的客户投诉,实施混沌工程同学的责任和义务是确保这些后续影响最小化且被考虑到。对于实验方案和目标进行充分的讨论是减少用户影响的最重要的手段,同时也可以通过一些技术手段去提前规避风险。
- 注入隔离:通过故障发生的地点来控制故障影响,从IDC到主机,从微服务到业务请求,都是可以精细控制的。
- 流量隔离:基于流量路由、环境隔离技术去控制业务影响范围,从小规模分散型实验逐渐过渡到集中型实验。
- 数据隔离:基于复制读请求、影子压测流量、测试流量等手段来隔离影响面。
一些实践场景举例
- 预案有效性:过去的预案测试的时候,线上没有问题,所以就算测试结果符合预期,也有可能是有意外但是现象被掩藏了。
- 监控报警:报警的有无、提示消息是否准确、报警实效是5分钟还是半小时、收报警的人是否转岗、手机是否欠费等,都是可以check的点。
- 故障复现:故障的后续Action是否真的有效,完成质量如何,只有真实重现和验证,才能完成闭环。发生过的故障也应该时常拉出来练练,看是否有劣化趋势。
- 架构容灾测试:主备切换、负载均衡,流量调度等为了容灾而存在的手段的时效和效果,容灾手段本身健壮性如何。
- 参数调优:限流的策略调优、报警的阈值、超时值设置等。
- 故障模型训练:有针对性的制造一些故障,给做故障定位的系统制造数据。
- 故障突袭、联合演练:通过蓝军、红军的方式锻炼队伍,以战养兵,提升DevOps能力。