监控治理 – 监控报警优化经验总结
当一个中大型互联网公司,每天由监控系统发出大量报警,而故障却始终无法及时发现的时候,如何能够快速找到问题的根源,如何改进,以及如何度量改进的效果,这一系列的问题就会摆在我们面前,本文基于作者在多家公司的监控治理经验,从评价体系角度出发,整理了十多个相关的指标,从而能够对监控系统以及各个业务线进行有效度量。
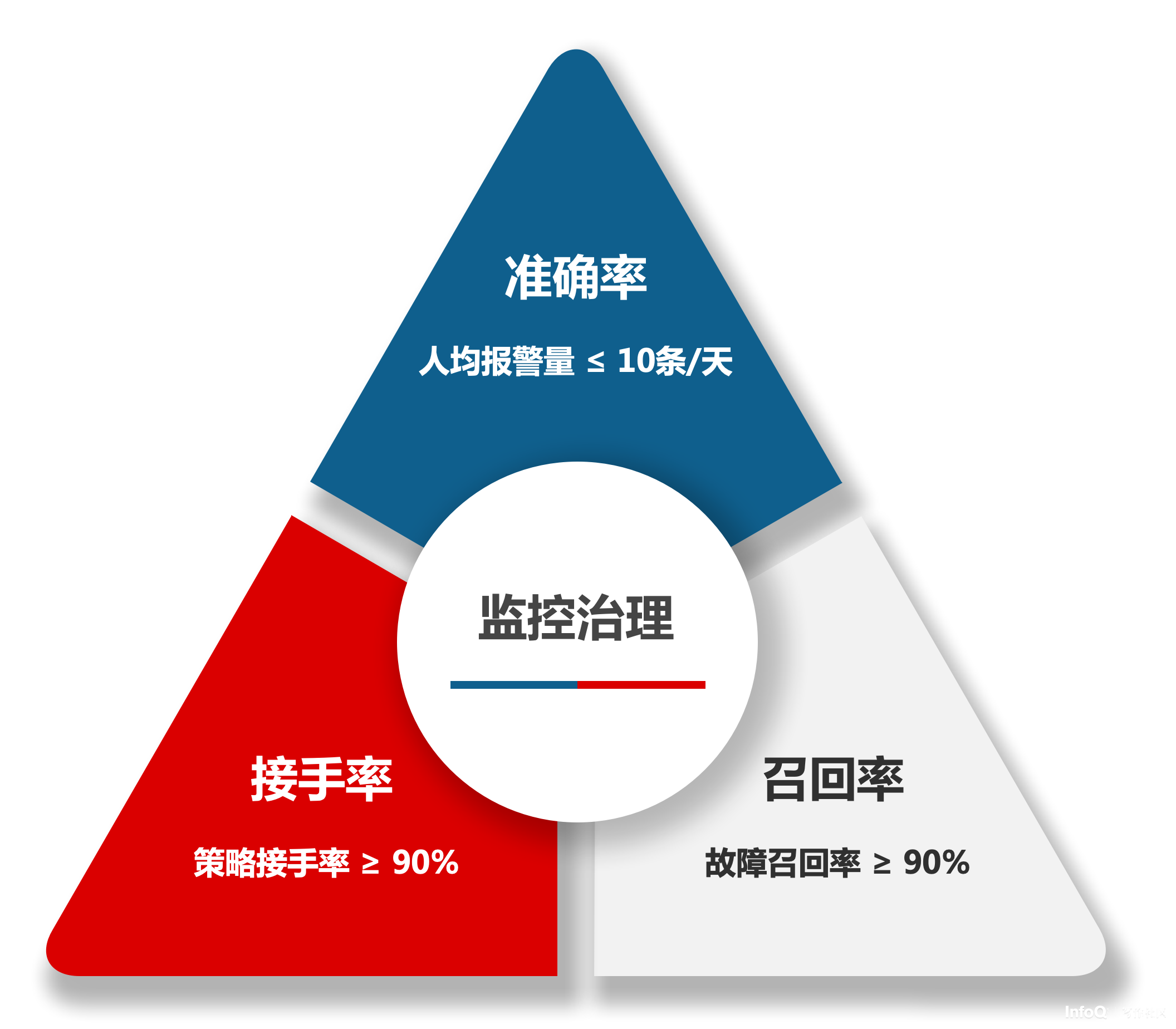
评价体系分为三类
- 第一类是效果指标,用于概要性说明监控治理的结果,通过召回率和发现时长来进行说明
- 第二类是核心指标,用于综合性评价监控治理的效果,也用来发现监控治理过程中的短板
- 第三类是参考指标,用于快速发现监控当中存在的一些初级问题
效果指标
监控召回率
含义:由监控系统的报警发现的故障占比
举例:100 个故障中有 70 个故障是基于监控报警发现的,那么召回率为 70%
参考:业界较好的监控召回率在 80-90%(分母:影响到业务核心指标的故障)
监控发现时长
含义:从故障发生到响应报警的时长
举例:一个故障在 00:00 发生,00:03 监控系统发出报警给相关人员,00:04 的时候报警发送给相关人员,00:05 相关人员响应该报警,那么发现时长为 5min
阶段:报警发送时长(00:00–00:04)+报警响应时长(00:04–00:05)
备注:故障的发现时长 ≠ 监控发现时长,还有一部分故障不是监控发现的
参考:业界较好的监控发现时长可以在 5min 内(含人员响应时间)
核心指标
人均报警数
含义:公司报警总量除以所有接收报警的人数
目标:主要是看报警的有效性、对人员的干扰度,因为单纯从报警总量,无法衡量好坏,只能看趋势,例如一个公司应该有多少报警?很难衡量。但是细分到人均后,就会有很深的体感。例如人均 500 条/天和人均 30 条/天
备注:在统计口径上,一般是看平均值,同时也要看 90/95 分位的人,报警量有多少,从而避免因报警接收人数较高而人为拉低了平均值。
策略接手率
含义:一个报警策略发出报警后,是否有被人查看,无所谓几个人查看了
举例:一条策略产生报警后假如发给 10 个人,只要有一个人看了,就视为策略接手,策略接手率 100%
分类:紧急报警的策略接手率和 IM 报警的策略接手率
参考:策略接手率应该达到 100%
备注:默认的接手率是没有时间要求的,多久看了都算,但对于部分要求较为严格的团队,有 5min 的接手率要求,这种统计口径,是只看 5min 内的响应情况,因此就不需要再考核接手延时了。
报警总量
含义:公司整体的报警数量
目的:主要是看波动趋势而非绝对值,从绝对值角度,很难精准定义 100 万服务器或者 100 万个服务或者 100 万个实例或者 100 万个研发应该有多少报警,因此在报警总量不反人类直觉的前提下,更多的是看变化趋势
分类:初始报警量 + 重复提醒报警量 + 升级报警量 + 恢复报警量
渠道:电话报警量+短信报警量+IM 报警量+邮件报警量
备注:如果一条报警消息中聚合了多条报警,算一条报警。对于监控系统自身来讲,可以通过报警消息的收敛比例来判断报警聚合的效果;同一个报警策略,发送了电话、短信、IM 和邮件,那么算四条报警而不能算一条报警,目的是合理控制干扰程度
接手延时
含义:报警接收人收到报警后,多久查看/接手的报警
举例:系统给接收人发送了一条报警到手机上,但该接收人 10min 后才看的报警,那么接手延时就是 10min
分类:紧急报警接手延时和 IM 接手延时
备注:一般来说,紧急报警都会打电话,因此紧急报警的接收延时都在 3min 内,IM 的报警是消息形式,因此接手延时在不同团队和个人差距较大。如果接手率统计的是 5min 的响应比例,则可以不考核接手延时指标。
参考:紧急报警的接手延时≤3min;IM 的接手延时≤10min
人员接手率
含义:一定数量的报警发送给某个接收人后,该接收人查看了多少报警
举例:给一个人发送了 100 条报警,该接收人查看了其中 20 条报警,那么人员接手率为 20%
分类:紧急报警的人员接手率和 IM 报警的人员接手率
区别:策略接手率关注的是策略有人处理即可,谁响应并不重要;人员接手率关注的是发送给此人的报警有多少被响应;当策略接手率为 100%而人员接手率较低时,说明报警的发送范围偏大了,有很多无关人员在接收报警,需要收敛报警的发送范围
参考:人员接手率应该达到 90%以上
过载人员比例
含义:有多少人的单日报警量超过了 144 条
计算:单条策略有异常、重复提醒和恢复三条报警,每个策略平均恢复时间为 15min,工作时间全部用于处理报警,那么单日的报警量上限为 12 小时 ÷ 15min * 3 条 = 144 条
备注:二八原则,10%的人甚至更少的人,接收了 90%以上的报警
报警收敛比
含义:异常事件的数量和报警消息数量的比例
目的:监控系统需要具备一定的报警聚合能力,从各种纬度对报警进行聚合,进而通过少量报警将问题全貌进行描述。缺乏聚合能力,会导致报警干扰太过严重,最终无人关注报警
备注:一般来讲,收敛比至少要达到 80%
报警策略配置合规性比例
含义:有多少报警策略的配置是符合规范以及最佳实践的
目的:通过确保报警策略配置合规性,来减小因策略配置本身导致的报警
报警接收人员比例
含义:报警接收人员数量/总人员数量的比例
目的:降低报警处理的人力成本,降低报警对团队的干扰程度
举例:团队有 100 人,所有人都接收报警,那么报警处理的人力就是 100 人,干扰程度就是 100 人 * 人均报警数 * 报警恢复时长
报警策略恢复时长
含义:报警策略从异常到恢复的时长统计
目的:假设重要的报警设置是合理的,那么报警就应该在较短的时间内恢复(例如 15min),如果重要报警的恢复时长远比 15min 高,那么就说明当前的报警策略设置存在不合理的地方
报警策略有效性比例
含义:有多少报警策略被长期被屏蔽、长期处于暂停状体或者一个季度以上的时间都没有报警过
目的:报警策略长期被暂停和屏蔽,是需要去解决其背后的问题,如果一直处于这种状态,是会有风险的
报警组值班开启率
含义:报警组是否开启值班的比例统计
目的:将报警值班进行收敛,从而大幅降低报警值班的人力成本
举例:一个报警组有 10 个人,任何报警都会同时发送给这 10 个人;如果开启值班,那么报警只会发给其中的一两个人,从而大幅降低了团队的报警值班成本
报警升级开启比例
含义:报警组是否开启报警升级功能的比例
目的:通过开启报警升级,确保报警始终有人跟进,避免值班人因为各种原因无响应的风险
备注:报警升级功能,应该默认开启,通过组织架构升级、自定义升级、服务节点升级等方式实现
报警升级比例
含义:有多少报警是发送给升级人员而非值班人员的
举例:如果一个月发送了一千条报警,其中有 30%以上的报警是发给报警升级人员的,那么可以认为,是报警值班机制出现了问题,该处理报警的人未处理报警,导致报警不断的发送给升级人员
报警策略平均接收人数
含义:一个报警策略发送给几个人
目的:评估整体的报警放大系数,避免一个报警发给十几人甚至几十人
备注:少部分核心策略可能会发给多人;部分团队的策略会发给主备值班人;部分团队要求研发、测试和运维都接收报警;因此,平均人数很难到
参考指标
TOP-N 策略
含义:单个策略一周内报警量>500 条或者占总量 5%以上视为 TOP-N 策略
目的:通过明确给出 TOP-N 的标准,进而明确 TOP-N 治理边界
监控策略报警数
含义:有多少个策略在统计周期内发生了报警
目的:用于识别问题的范围,是局部还是大面积的
举例:在统计周期内,有 10 个策略发生报警和 300 个策略发生报警,前者可能问题的集中度很高,后者就较为分散,所需的应对手段自然也不同
首次报警占比
含义:单个策略会有首次报警、重复提醒、报警升级、报警恢复等状态
目的:提升首次报警占比,降低重复提升和报警升级的占比,是一个相对健康的状态,如果值班人员不处理报警,不断靠重复提醒和升级才能响应这种状态肯定是不对的
重复报警策略
含义:单个策略一周内重复报警大于 3 天的策略
目的:对于不属于 TOP-N 的策略,从另外一个维度进行约束
举例:某个策略一周报警 21 条,每天报警 3 次,连续 7 天均报警了,从 TOP-N 的角度看,他永远不属于治理范畴,但对团队的干扰,其实是非常严重的
报警值班耗时占比
含义:报警接收人员用于处理报警的时长占总时长的比例
举例:一周的时间内,报警接收人员处理了 100 个报警,100 个报警的发生到恢复时长的累计值为 24 个小时,那么值班耗时占比就是 1/7,约 15%的时间用于处理报警
如果我们当前的痛点并非要对整个公司进行监控治理,而是希望快速解决团队目前面临的问题,那么大家也可以参考我们之前的治理文章《摆脱无效报警?十年运维监控报警优化经验总结》来快速解决问题
运维工程师面试者第一个问题是:需要值班吗?笔者自己也曾经历过月入十万的时期,在那个时候,数个系统同时发布下一代版本,而老系统还需要过渡很长时间,工作量直接翻倍,大家只能勉强应付一线运维工作,团队成员开始陆续离职,而新人又无法在短时间内上手,整体情况不断恶化,持续半年左右才缓过劲来。
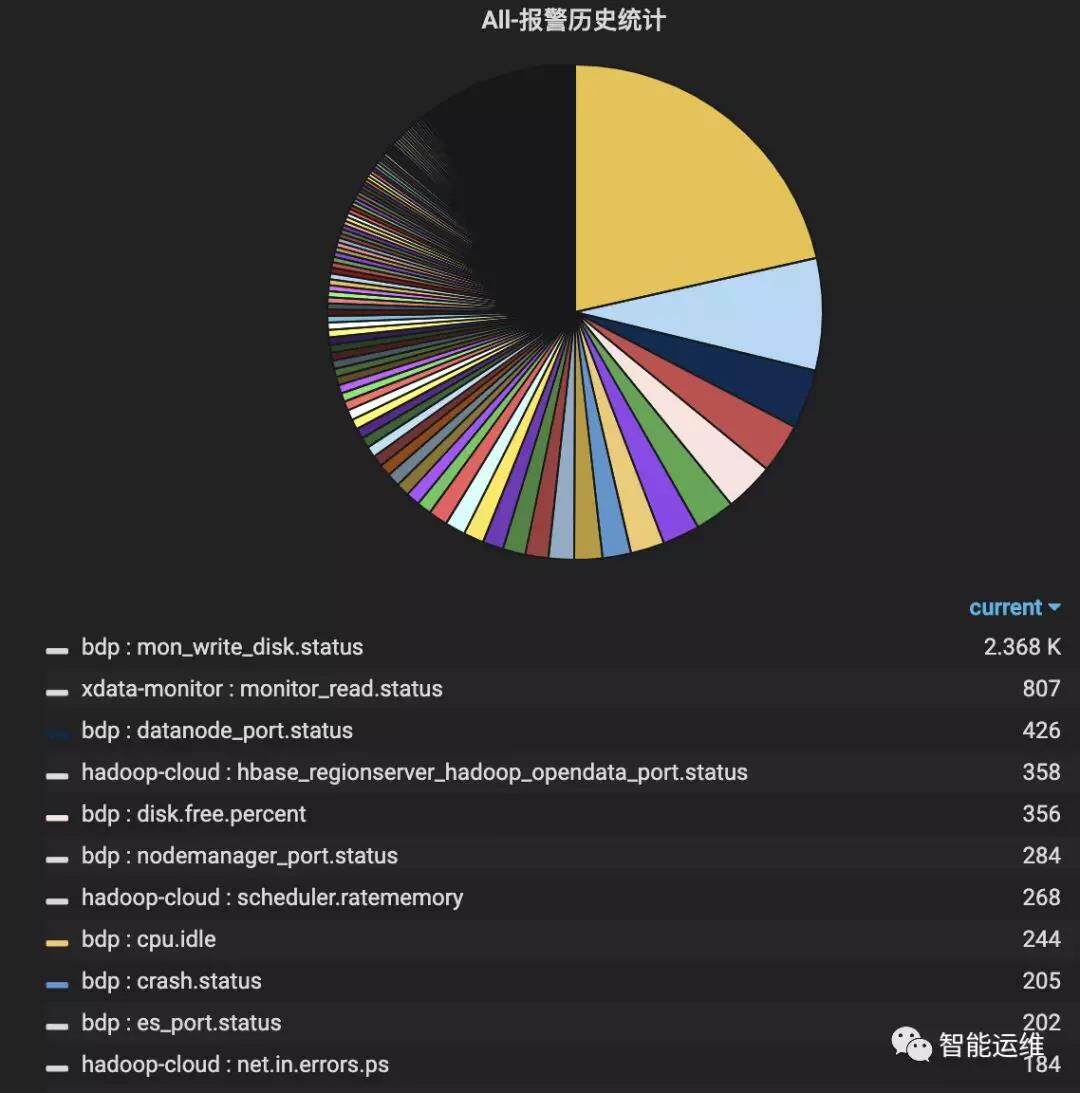
下面两张截图是我挑选的两个团队一周报警数的对比图,前者的单日报警量最高是 55348 条,后者单日的报警量最高为 34 条,两者相差 1600 倍,而前者才是国内很多互联网运维团队的真实写照。


在管理大规模集群的情况下,究竟有多少报警量才是合理的呢?Google SRE 每周只有十条报警,如果超过十条,说明没有把无效报警过滤掉(Google SRE 仅负责 SLA 要求为 99.99%的服务)。笔者所在的团队要求则是,每周至多两晚有报警,单日报警量不能超过 50 条(比 Google SRE 放水好多啊)。
通过控制单日报警数量,严格约束夜间报警天数,确保最少不低于四人参与值班,笔者所在的团队,近几年来,不仅少有因为值班压力而离职的同学,而且我们每年都能持续招聘到 985 前 20 名学校的多个研究生。那么,怎么做到呢,以下是笔者的一些经验分享。
运维工程角度看报警优化
报警值班和报警升级
基于值班表,每天安排两人进行值班处理报警,将值班压力从全团队压缩在两人范围内,从而让团队能够有足够的时间和人力进行优化工作。同时,为了避免两个值班人员都没有响应报警,可以使用报警升级功能,如果一个报警在 5min 内值班人员均未响应,或者 15min 内未处理完毕,或者有严重故障发生,都可以将报警进行升级,通告团队其他成员协助处理。
如果公司的监控系统暂不支持值班表功能,则通过人工定期修改报警接收人的方式进行。而对于监控系统不支持报警升级的问题,通过自行开发脚本的方式,也能在一定程度上得到解决。也可以将报警短信发送至商业平台来实现。总之一句话,办法总比问题多。
对于报警值班人员,需要随时携带笔记本以方便处理服务故障,这个要求,和报警数量多少以及报警的自动化处理程度并无关系,仅和服务重要性有关。对于节假日依然需要值班的同学,公司或者部门也应该尽量以各种方式进行补偿。
基于重要性不同,分级应对
一个问题请大家思考一下,如果线上的服务器全部掉电后以短信方式通知值班人员,那么线上一台机器的根分区打满,也通过短信来通知是否有必要。
上述的问题在日常工作也屡屡发生,对于问题、异常和故障,我们采取了同样的处理方式,因此产生了如此多的无效报警。
Google SRE 的实践则是将监控系统的输出分为三类,报警,工单和记录。SRE 的要求是所有的故障级别的报警,都必须是接到报警,有明确的非机械重复的事情要做,且必须马上就得做,才能叫做故障级别的报警。其他要么是工单,要么是记录。
在波音公司装配多个发动机的飞机上,一个发动机熄火的情况只会产生一个”提醒“级别的警示(最高级别是警报,接下来依次是警告,提醒,建议),对于各种警示,会有个检查清单自动弹出在中央屏幕上,以引导飞行员找到解决方案。如果是最高级别的警报,则会以红色信息,语音警报,以及飞机操纵杆的剧烈震动来提示。如果这时你什么都不做,飞机将会坠毁。
故障自愈
重启作为单机预案,在很多业务线,可以解决至少 50%的报警。没有响应,重启试试,请求异常,重启试试,资源占用异常,重启试试,各种问题,重启都屡试不爽。
换言之,针对简单场景具有明确处置方案的报警,自动化是一个比较好的解决方案,能够将人力从大量重复的工作中解放出来。
自动化处理报警的过程中,需要注意以下问题:
- 自动化处理比例不能超过服务的冗余度(默认串行处理最为稳妥)
- 不能对同一个问题在短时间内重复多次的自动化处理(不断重启某个机器上的特定进程)
- 在特定情况下可以在全局范围内快速终止自动化处理机制
- 尽量避免高危操作(如删除操作,重启服务器等操作)
- 每次执行操作都需要确保上一个操作的结果和效果收集分析完毕(如果一个服务重启需要 10min)
报警仪表盘,持续优化 TOP-3 的报警
如下图示,全年 TOP-3 的报警量占比达到 30%,通过对 TOP-3 的报警安排专人进行跟进优化,可以在短时间大幅降低报警量。
TOP-3 只是报警仪表盘数据分析的典型场景之一,在 TOP-3 之后,还可以对报警特特征进行分析,如哪些模块的报警最多,哪些机器的报警最多,哪个时间段的报警最多,哪种类型的报警最多,进而进行细粒度的优化。
同时,报警仪表盘还需要提供报警视图的功能,能够基于各种维度展示当前有哪些报警正在发生,从而便于当短时间内收到大量报警,或者是报警处理中的状态总览,以及报警恢复后的确认等。
基于时间段分而治之
下图是国内非常典型的一类流量图,流量峰值在每天晚上,流量低谷在每天凌晨。从冗余度角度来分析,如果在流量峰值有 20%的冗余度,那么在流量低谷,冗余度至少为 50%。基于冗余度的变换,相应的监控策略的阈值,随机也应该发生一系列的变化。
举例来说,在高峰期,可能一个服务故障 20%的实例,就必须介入处理的话,那么在低谷期,可能故障 50%的实例,也不需要立即处理,依赖于报警自动化处理功能,逐步修复即可。
在具体的实践中,一种比较简单的方式就是,在流量低谷期,仅接收故障级别的报警,其余报警转为静默方式或者是自动化处理方式,在流量高峰期来临前几个小时,重新恢复,这样即使流量低谷期出现一些严重隐患,依然有数小时进行修复。这种方式之所以大量流行,是因为该策略能够大幅减少凌晨的报警数量,让值班人员能够正常休息。
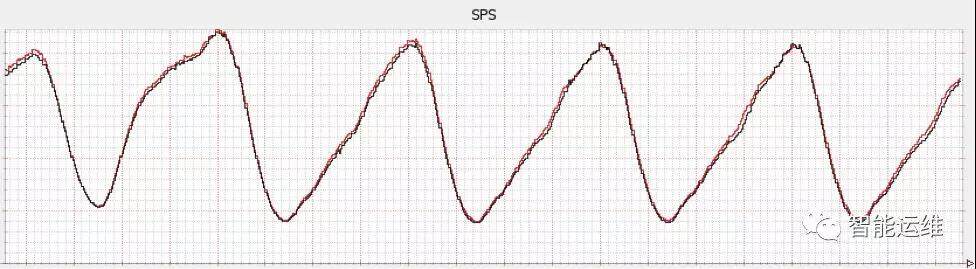
报警周期优化,避免瞬报
在监控趋势图中,会看到偶发的一些毛刺或者抖动,这些毛刺和抖动,就是造成瞬报的主要原因。这些毛刺和抖动,至多定义为异常,而非服务故障,因此应该以非紧急的通知方式进行。
以 CPU 瞬报为例,如果设置采集周期为 10s,监控条件为 CPU 使用率大于 90%报警,如果设置每次满足条件就报警,那么就会产生大量的报警。如果设置为连续 5 次满足条件报警,或者连续的 10 次中有 5 次满足条件就报警,则会大幅减少无效报警。对于重要服务,一般建议为在 3min 内,至少出现 5 次以上异常,再发送报警较为合理。
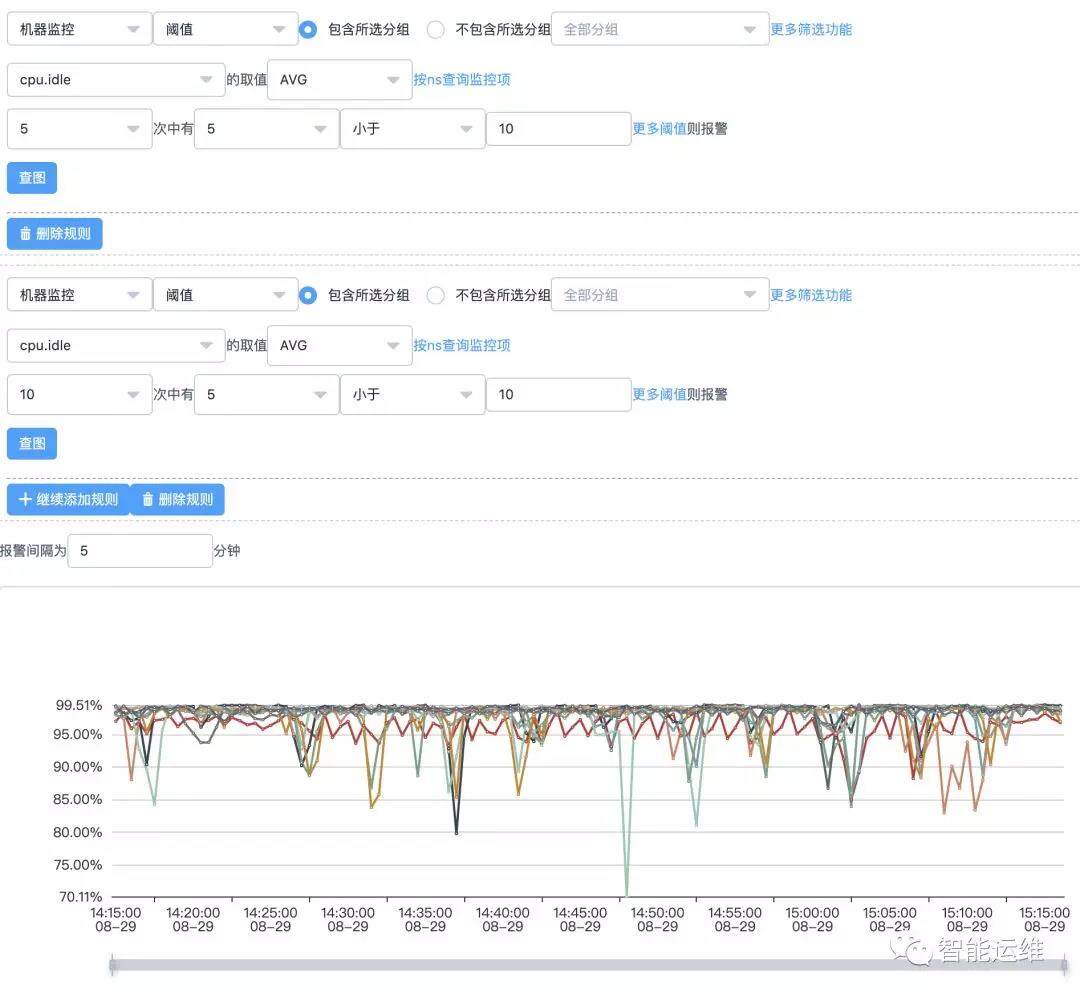
提前预警,防患于未然
对于很多有趋势规律的场景,可以通过提前预警的方式,降低问题的紧迫程度和严重性。下图是两台机器一周内的磁盘使用率监控图,可以预见,按照目前的增长趋势,必然会在某一个时间点触发磁盘剩余空间 5%的报警,可以在剩余空间小于 10%的时候,通过工单或者其他非紧急方式提醒,在工作时间段内,相对从容的处理完毕即可,毕竟 10%到 5%还是需要一个时间过程的。
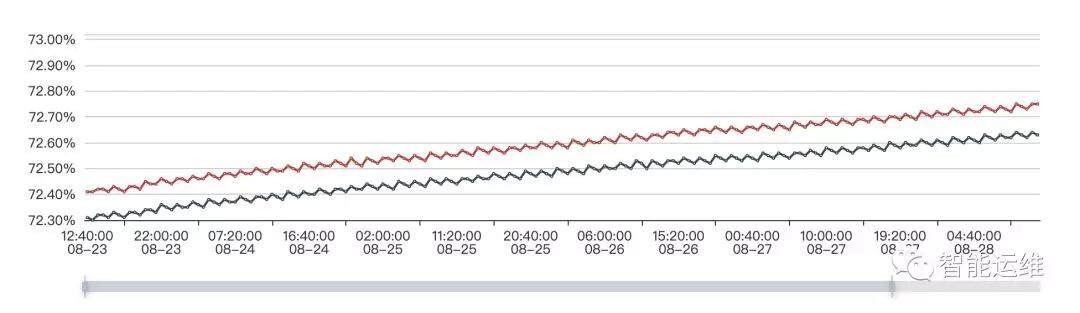
日常巡检
提前预警面向的是有规律的场景,而日常巡检,还可以发现那些没有规律的隐患。以 CPU 使用率为例进行说明,近期的一个业务上线后,CPU 使用率偶发突增的情况,但是无法触发报警条件(例如 3 分钟内有 5 次使用率超过 70%报警),因此无法通过报警感知。放任不管的话,只能是问题足够严重了,才能通过报警发现。这个时候,如果每天有例行的巡检工作,那么这类问题就能够提前发现,尽快解决,从而避免更加严重的问题发生。
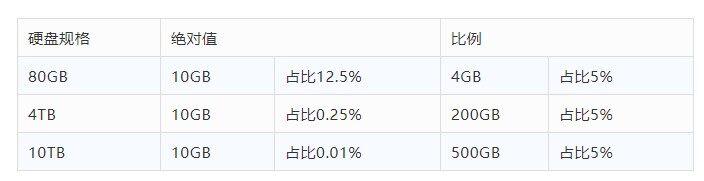
比例为主,绝对值为辅
线上机器的规格不同,如果从绝对值角度进行监控,则无法适配所有的机器规格,势必会产生大量无意义的报警。以磁盘剩余空间监控为例,线上规格从 80GB 到 10TB 存在多种规格,从下图表格看,比例比绝对值模式能更好的适配各种规格的场景(EXT4 文件系统的默认预留空间为 5%,也是基于比例设置的并可通过 tune2fs 进行调整)
对于一些特殊场景,同样以磁盘剩余空间为例进行说明,例如计算任务要求磁盘至少有 100GB 以上空间,以供存放临时文件,那这个时候,监控策略就可以调整为:磁盘剩余空间小于 5%报警或磁盘剩余空间绝对值小于 100GB 报警
同环比监控
同环比监控适用于有明显时间特征规律的数据,和上述提到的基于时间段分而治之的策略,两者的区别为:同环比需要较为明显的基于时间的特征规律,从而提供精准的监控,而后者则以时间段为划分粒度,对特征的精度不做要求。在不具备同环比监控能力的时期,基于时间段分而治之未尝不是一种选择。
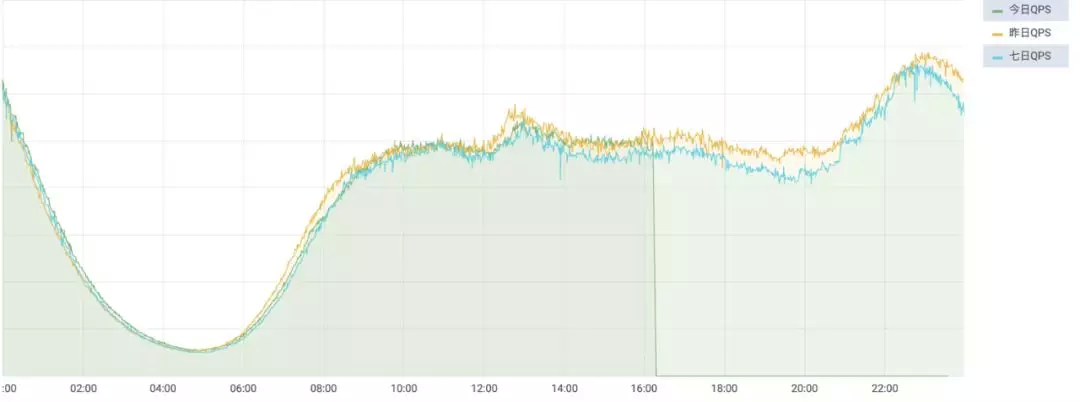
以同环比监控的典型场景流量图为例说明,在具体的一个时间点上,可以看到当前的 QPS,昨日该时间点的 QPS(环比),以及前几周相同时间点的 QPS(同比),因此当前时间的 QPS 是否异常,并不需要关注具体值,只需要和同环比的数据进行比较,其振幅在限定的范围即可,而振幅的大小则决定了监控的敏感程度。这样,通过同环比监控的使用,在不需要人工设置具体阈值以及频繁调整的情况下,就实现了流量小幅涨跌的精准监控,从而大幅减少报警数量。
同环比监控的落地需要一定的技术门槛和一定的业务体量,目前并非大部分公司监控系统的标配,且据笔者所知,误报率也是很多公司无法解决的硬伤。据我们落地的经验看,误报有如下来源,算法自身的有效性,对于节假日的处理,对于监控系统的数据缺失、数据不完整等的容错等。
Code Review
前人埋坑,后人挖坑。在解决存量问题的情况下,不对增量问题进行控制,那报警优化,势必会进入螺旋式缓慢上升的过程,这对于报警优化这类项目来说,无疑是致命的。通过对新增监控的 Code Review,可以让团队成员快速达成一致认知,从而避免监控配置出现千人千面的情况出现。
沉淀标准和最佳实践
仅仅做 Code Review 还远远不够,一堆人开会,面对一行监控配置,大眼瞪小眼,对不对,为什么不对,怎么做更好?大家没有一个标准,进而会浪费很多时间来进行不断的讨论。这时候,如果有一个标准,告诉大家什么是好,那么就有了评价标准,很多事情就比较容易做了。标准本身也是需要迭代和进步的,因此大家并不需要担心说我的标准不够完美。基于标准,再给出一些最佳的监控时间,那执行起来,就更加容易了。
以机器监控为例进行说明,机器监控必须覆盖如下的监控指标,且阈值设定也给出了最佳实践,具体如下:
- CPU_IDLE < 10
- MEM_USED_PERCENT > 90
- NET_MAX_NIC_INOUT_PERCENT > 80 (网卡入口/出口流量最大使用率)
- CPU_SERVER_LOADAVG_5 > 15
- DISK_MAX_PARTITION_USED_PERCENT > 95 (磁盘各个分区最大使用率)
- DISK_TOTAL_WRITE_KB(可选项)
- DISK_TOTAL_READ_KB(可选项)
- CPU_WAIT_IO(可选项)
- DISK_TOTAL_IO_UTIL(可选项)
- NET_TCP_CURR_ESTAB(可选项)
- NET_TCP_RETRANS(可选项)
彻底解决问题不等于自动处理问题
举两个例子,大家来分析一下这个问题是否得到彻底解决:
- 如果一个模块经常崩掉,那么我们可以通过添加一个定时拉起脚本来解决该问题。那这个模块崩掉的问题解决了吗?其实并没有,你增加一个拉起脚本,只是说自己不用上机器去处理了而已,但是模块为什么经常崩掉这个问题,却并没有人去关注,更别提彻底解决了。
- 如果一个机器经常出现 CPU_IDLE 报警,那么我们可以将现在的监控策略进行调整,比如说,以前 5min 内出现 5 次就报警,现在可以调整为 10min 内出现 20 次再报警,或者直接删除这个报警策略,或者将报警短信调整为报警邮件,或者各种类似的手段。但这个机器为什么出现 CPU_IDLE 报警,却并没有人去关注,更别提解决了。
通过上面两个例子,大家就理解,自动化处理问题不等于解决问题,掩耳盗铃也不等于解决问题,什么叫做解决问题,只有是找到问题的根本原因,并消灭之,才能确保彻底解决问题,轻易不会再次发生。还是上面自动拉起的例子,如果仔细分析后,发现是内存泄露导致的进程频繁崩掉,或者是程序 bug 导致的 coredump,那么解决掉这些问题,就能够彻底避免了。
如何解决团队内部的值班排斥情绪
每个运维团队早晚都会面对团队高工对值班工作的排斥,这也是人之常情。辛辛苦苦干了几年了,还需要值班,老婆孩子各种抱怨,有时候身体状况也不允许了,都不容易。不同的团队,解决方式不同,但有些解决方案,会让人觉得,你自己都不想值班,还天天给我们打鸡血说值班重要。更严重一些的,会让团队成员感受到不公平,凭什么他可以不值班,下次是不是我们大家也可以找同样的理由呢。
笔者的团队是这样明确说明的:
- 保证值班人员数量不低于四人,如果短时间内低于四人,那么就需要将二线工程师短暂加入一线值班工作中,为期不超过三个月
- 对于希望退出值班列表的中级工程师,给三个月不值班时间,如果能将目前的报警短信数量优化 20%-50%,则可以退出值班序列,但如果情况反弹,则需要重回值班工作
- 团队达到一定级别的工程师,就可以转二线,不参与日常值班工作,仅接收核心报警,且对核心报警的有效性负责,若服务故障核心报警未发出,则每次罚款两百
- 团队负责人不参与值班工作,但需要对单日报警数量负责,如果当周的日报警数量大于要求值,则每次罚款两百元。如果团队成员数量低于四人时,则需要加入值班列表
写在最后
在团队的报警量有了明显减少后,就需要对报警的准确性和召回率进行要求了,从而才能持续的进行报警优化工作。所谓的准确性,也就是有报警必有损,而召回率呢,则是有损必有报警。